It’s easier to explain social A/B testing using this analogy:
Pretend you’ve never seen a dog before. (Work with me here.) You’re standing on your favorite sidewalk and see one go by. And it’s pink. Based on having no prior knowledge of what dogs are supposed to look like, you likely now believe that all dogs are pink. How weird.
Then you see a second dog go by. It’s black. With this new knowledge, you now consider that 50% of dogs are pink and 50% are black. You have no way of knowing at this point that a pink dog is an outlier, something you may never see again.
Let’s bring it back to reality. You know what dogs look like. When you see a pink dog, you immediately recognize it as unusual, indeed, impossible without dye. However, you may now allow that some small percentage of dogs are pink. Congratulations, you’ve applied Bayesian thinking to the color of dogs!
What does this have to do with A/B testing? As obvious as it is for us to recognize outliers in the color of dogs, it’s much harder to apply this thinking when looking at conversions, clicks or engagement. Let’s take an example.
Instead of standing on the sidewalk enjoying fresh air, you’re now sitting at your desk, observing the results from your latest A/B test. You see that variation 1 of your test has a respectable 5% click-through rate. Variation 2 looks even better at 26%. You pat yourself on the back for finding the headline that will engage 400% better!
“But wait,” I hear you saying. “A 26% click-through rate? That sure looks a lot like a pink dog.” And indeed it probably is. You’ve now applied Bayesian thinking to A/B testing, and by doing so, you’ve stopped yourself from sending that @channel Slack message proclaiming your A/B testing prowess. Instead, you’ll first apply rigorous analysis to your results.
Here’s how to do it.
Our goal
Let’s make this a little more concrete. We’ll be using a real-world example courtesy of one of our publishing partners Social A/B Tool to run A/B tests. This particular client wants to test the introduction copy of a Facebook post. Here are the variations:
Variation 1:
“Follow Mikey Rencz, Mikkel Bang, and Mark Sollors around in episode three of Burton Presents. Watch Below.”
Variation 2:
“The life of a Burton pro.”
We want to learn which of these two posts will perform best on Facebook, and by how much. To do this, we’ll post each variation to a small representative sample of the publisher’s audience and track each variation’s performance over time. Fortunately, Social A/B automates this process for you. After some time (usually a few minutes), we’ll receive data from Facebook. That’s when the real fun starts.
The naive approach to A/B test result analysis
The easiest way to calculate performance of a post is the following:
- Get the clicks and reach for each variation
- Divide clicks by reach to get the click-through rate (CTR)
- Calculate how much better one is than the other
More sophisticated testers will use a sample size calculator to validate that the sample is large enough to be significant. This is a critical step. But we don’t believe it’s enough. Here’s why…
Let’s say that after exposing the two variations to a representative sample audience for 20 minutes, we receive these results:
- Variation 1: 46 clicks, 866 impressions = 5.3% CTR
- Variation 2: 8 clicks, 676 impressions = 1.2% CTR
Variation 1 outperformed variation 2 in this example by 340%. Legit? A quick chi-squared test validates that we have enough data to form a conclusion, and so we’re feeling confident.
But now let’s give it the pink dog test. When’s the last time you had a post drive over 5% click-through rate? Never? Okay, is this post breaking news, or about the white and gold dress? No? It’s a story about pink dogs? Perhaps the click-through rate is worth another look.
This approach ignores the reality of what usually happens on your posts, opening the door for wildly inaccurate assumptions. It may still accurately predict the better variation, but how much better? If variation 1 got 46 clicks on 866 impressions, will it really get 460 on 8,660 impressions? It’s possible, but when forming an important editorial decision and claiming A/B testing victories, it’s better to air on the side of cautious optimism than on hopeful exuberance. So let’s use the same data, but take our prior knowledge into account.
The Bayesian approach
When you recognized the pink dog as an anomaly, you did so because of your prior knowledge (or belief) about the natural color of dogs. You also added this new data point (a single pink dog) to your knowledge, making it the new prior belief for your future self. This is the fundamental concept of Bayesian thinking. And it’s what we need to do when analyzing test results. Why? Because you have a ton of knowledge about how your content and audience usually perform. There’s no reason to ignore that knowledge when predicting future performance.
The first challenge we face is to quantify our prior belief about Facebook post performance. This mathematical prior belief needs to represent two things:
- Your usual click-through rate
- The typical variance of click-through rates between posts
For the publisher in our example, most Facebook posts see between 1% and 2% click-through rate, without much variance. We could represent this as a mean and a standard deviation, but more useful for the calculations we need to make are to represent the knowledge as what’s called alpha (α) and beta (β) parameters. Begin: magic.
The α and β for this publisher are 12.92 and 842.22, respectively. We’ll discuss how these are calculated on a rainy day. For now, just know that they represent the expected click-through rate of a post, and that their magnitude is inversely correlated to the click-through rates’ variance.
To double check our work, let’s use our α and β to calculate our expected click-through rate. We can do that with a simple formula:
Expected CTR = α / (α + β) = 12.92 / (12.92 + 842.22) = 1.5%
This matches our prior belief about the publisher’s post performance. How do we use this to predict future click-through rates on our posts? It’s magic because it’s dead simple:
Predicted CTR = (clicks + α) / (reach + α + β)
What? 8th grade math? Gotta love it. So let’s use this to calculate our predicted click-through rate as data came in from our real-world test we touched on above:
| Minute | Variation 1 Clicks/Reach – CTR | Variation 2 Clicks/Reach – CTR | Variation 1 Predicted CTR | Variation 2 Predicted CTR |
|---|
| 0 | 0/0 – 0% | 0/0 – 0% | 1.5% | 1.5% |
| 5 | 2/200 – 1% | 4/174 – 2.3% | 1.41% | 1.64% |
| 10 | 12/260 – 4.6% | 4/290 – 1.4% | 2.23% | 1.48% |
| 15 | 36/698 – 5.2% | 6/578 – 1% | 3.15% | 1.32% |
| 20 | 46/866 – 5.3% | 8/676 – 1.2% | 3.42% | 1.37% |
At minute 0, before we’ve tested our post, the formula gives us a predicted click-through rate that’s equal to our prior belief. Makes sense, since if we don’t have any new information, our most likely outcome is equal to our prior belief.
Now take a look at minute 20, where we observed a 5.3% click-through rate for variation 1. It’s tempting to proclaim how good this variation is, but when we take our prior knowledge into account—both the average click-through rate for this publisher and the expected variance as represented in our α and β parameters—we see it’s much more likely that the actual click-through rate is 3.4%.
To round out the intuition on this example, let’s pretend we have a much bigger population, and that variation 1’s click-through rate is actually 5.3%. To see how this formula works, we’ll multiply variation 1’s 20-minute results by 1,000.
Predicted CTR = (46000 + 12.92) / (866,000 + 19.92 + 842.22)
Predicted CTR = 5.3%
You may notice two things:
- As we get more data, we become more confident that the observed click-through rate actually is our predicted click-through rate
- The larger the α and β parameters, the more data we need to move our prediction
Congratulations, you have completed the Bayesian portion of the analysis! Now let’s use our predictions to pick a winner.
Measuring precision
Before we talk about precision, we have to talk about probability density functions. Contain yourself, the most exciting part is yet to come!
The α and β parameters form the basis for the probability density function (PDF) of a beta distribution. In English, this tells us the likelihood that our click-through rate is a certain value. Example:
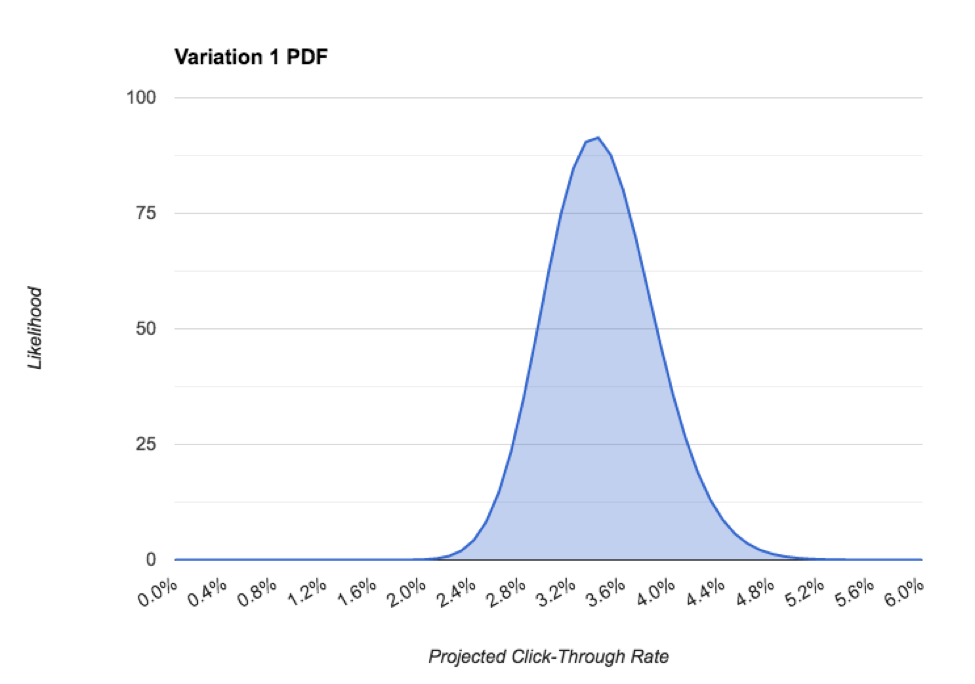
In the above PDF, we can see the most likely click-through rate for this post is about 3.4% measuring is the credible interval, which is the 95% distribution of the PDF, which in our case is roughly 2.2%. As we collect more data and become more confident in our prediction, precision improves, which is critical to actually picking a winner. We’ll tackle that next.
Calculating probability
We’ve finally arrived. It’s time to figure out if our better variation is actually a winner! Let’s start by visualizing it.
Here’s the PDF of both variations, on one chart:
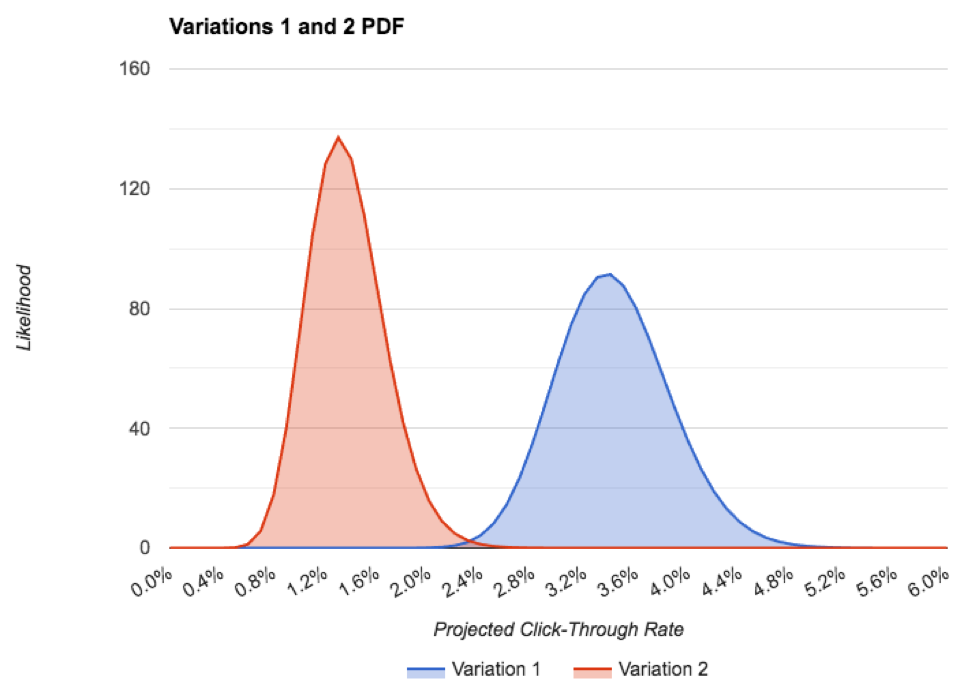
You can see that the precision of variation 1 is less than variation 2, even though we have slightly more data. This is because it has strayed pretty far away from the expected, prior click-through rate. Even still, there is hardly any overlap between the PDFs, which is a very good thing for our test!
The only way variation 2 is actually better than variation 1 is if the actual future click-through rate of variation 2 was more than 2% and the actual future click-through rate of variation 1 was less than about 2.2%, each of which is highly unlikely. This is represented by the small overlap of the two PDFs. For both anomalies to occur would be like flipping dozens of heads in a row on a fair coin. Not going to happen.
So at this point, we’re very confident that variation 1 is the winner and that it should drive about a 3.4% CTR, versus variation 2’s 1.4%.
Now we can see it, let’s calculate it.
The fun (slow) way
The fun way to measure the probability that one variation is truly better than the other is to run a Markov Chain Monte Carlo simulation. For our test results, after 1,000,000 iterations, we get a 0.999 probability that variation 1 is the best. Great!
The downside is an MCMC actually requires software to do something a million times. Who’s got that kind of time?
The boring (fast) way
Lucky for us, there are smart people who have devised clever formulas so we don’t have to simulate it ourselves.
After plugging in our numbers and waiting a couple milliseconds, we see that variation 1 is better than 2 with a 1.0 probability. Victory is ours!
Let’s recap all the steps we’ve taken to conclude our test is successful:
- We formed a prior belief of the expected click-through rate of our posts, represented by α and β parameters
- We showed each variation to a representative sample of our audience, collecting click and reach data from Facebook as we went
- We used our prior belief and the data we pulled from our test to calculate each post’s likely click through rate
- We looked at the PDF of our posteriors to ensure we had enough data, as informed by a required precision
- We used a fancy formula to compute the probability that our better-performing variation is actually the best
Now is the time to @channel #general the results of your A/B test, knowing that your winner is legit and that it will drive more social engagement and clicks back to your amazing content. Which is hopefully about pink dogs.
Further reading
The concepts in this blog post and the methods used by our tool benefitted greatly from the thoughtful work of several data scientists and statisticians. We highly recommend diving deeper into these concepts by reading their work:
- How A/B Testing Works
- Ignorant No More: Crash Course on A/B Testing Statistics
- Statistical Significance Does Not Equal Validity
- How Not to Run An A/B Test
- A/B Testing with Hierarchical Models in Python
- Bayesian Bandits
- Statistical Advice for A/B Testing
- Formulas for Bayesian A/B Testing
- Understanding empirical Bayesian hierarchical modeling
- This entire series, “using baseball statistics” is outstanding.
Want to learn more?
A/B testing your content on Facebook is a complex subject. We got you covered — you can read more about:
- Optimizing content for Facebook’s changing algorithm
- Crafting effective intro copy
- Designing click-worthy Facebook Ads
Put yourself in the driver seat and start A/B testing your content for Facebook. It takes you less than a minute to sign up for our Social A/B tool and it’s completely free — so why not take a spin?