
Data is literally everywhere, and it’s increasing. To quote CloverDX, “74 zettabytes of data will be created in 2021. That’s up from 59 zettabytes in 2020 and 41 zettabytes in 2019.” To put that into context consider that a zettabyte is a trillion gigabytes, which would fill nearly 2 billion 512GB iPhones.
Where Is All This Data Coming From?
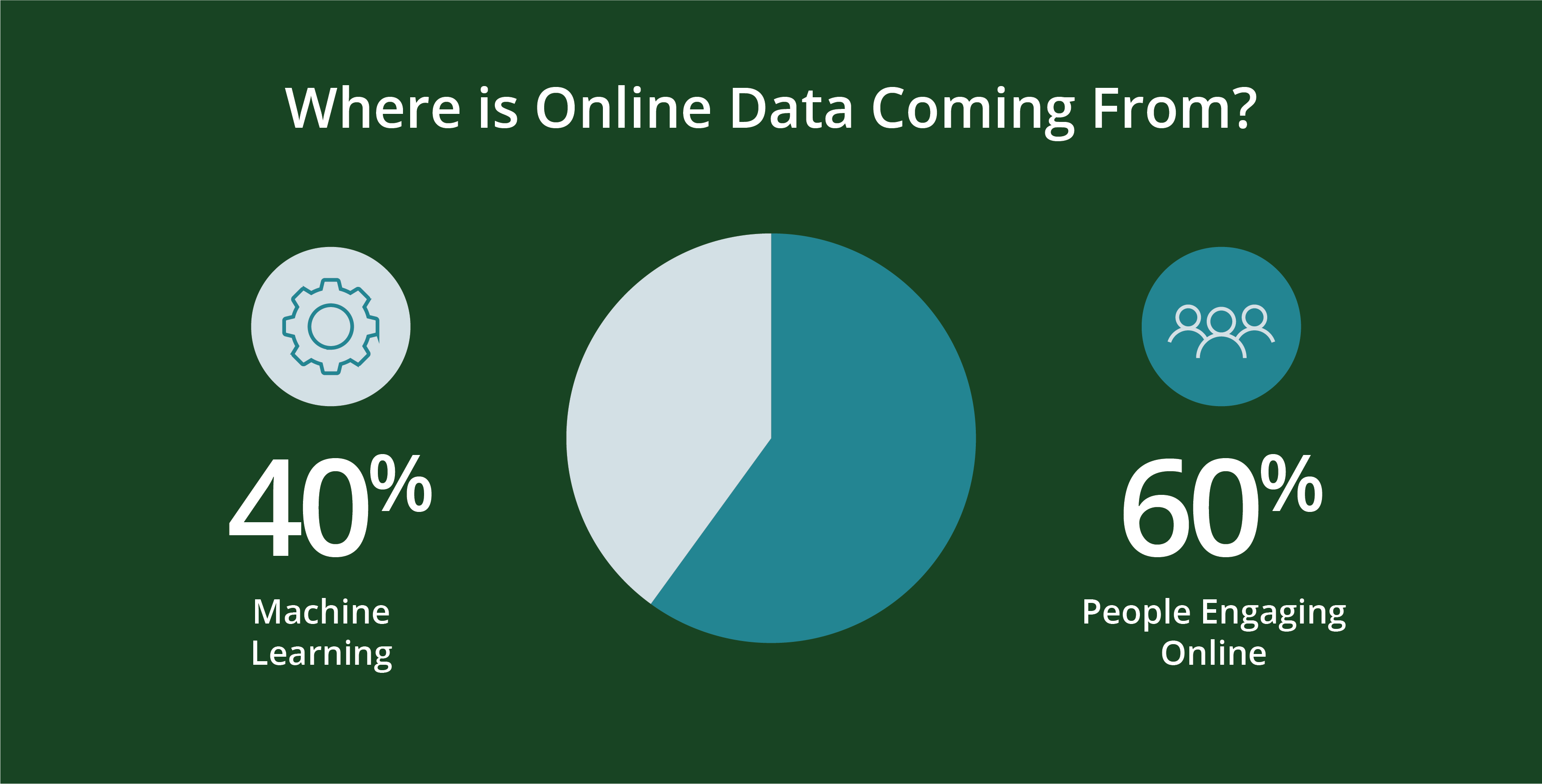
People—and the programming they create—generate data. More specifically, roughly 60 percent of today’s online data are generated by people, with the remaining 40 percent being machine-generated in scripts like web logs, APIs, security endpoints, message queues and sensor data.
Consider that just over half of the world’s population is digitally active—that’s nearly 5 billion people. Of course, digital life has penetrated different parts of the globe at different rates. While 90% of North Americans and Europeans are digitally active, other areas are growing at phenomenal rates—like Africa, which is up 12,441% from 2000 to 2020. New internet users in 2020 numbered 319 million, and is growing at 7% or nearly a million new users every day. With more people comes more search activity. Google, which owns 91.9% of the internet search market, processes 8.5 billion searches per day. That’s up from 5.6 billion in 2021 and roughly 99,000 searches every second. Talk about data growth!
Which Is Why There Are So Many Data Providers
Businesses need data providers. All this data exists in different formats and locations. Some of it can be combined safely and profitably with modest effort. Others require more. But in general, all data must be ‘clean’ and structured. That way it can be combined with other, complementary data sources for analysis and then visualized for action. This is the work of data providers.
And because there are many sources and types of data useful for businesses, there are also many ways to make that data useful. This can make it difficult to compare different vendors and services from one project to another. Each project focuses on different outcomes, industries, types of customers, etc., and each data provider can’t fit every parameter perfectly. Beyond the data variabilities, there are also different methodologies–often proprietary–that can make comparison challenging.
Of course, data providers are also not created equal. With so much data available, much of it isn’t valuable, or isn’t sourced soundly, or is aggregated with low-grade data science. Those factors can affect performance and the data’s actual value. Keeping these and a few other key factors in mind can help ensure a win-win collaboration.

Why Manipulating Data Isn’t Always A Bad Thing
All data is manipulated. It must be, to be usable. For example, maybe it’s sorted into alphabetical order, or an order based on zip codes or prior product use. Perhaps it’s manipulated to suit website management protocols focusing on web logs or customerID security.
This type of manipulation makes the data useful to businesses, and allows the data to be combined, analyzed and ultimately visualized. But how much manipulation is good, and how much is too much?
Large datasets give companies wider ranges of data, which can ensure that conclusions are representative of a market-worthy audience set. However, combining datasets must also address numerous factors from firmographics and timelines to alignment of data categories to ensure conclusions meet the desired scope and scale.
Large datasets can also become unwieldy, reflecting the challenges of identifying specific and actionable insights that are often more apparent with small subsets of data, but still require the scale and coherency of the larger, richer dataset to validate results.
In fact, the most important data manipulations have to do with quantity and quality—and they’re necessary.
The Ingredients Of Good Data—Verified, Validated, Privacy-compliant
Much of the standard manipulations that firms apply to data have to do with quality, which has three large factors: validation, verification, and privacy.
- Verification ensures data records are associated with real people, and not bots, and that they’re accurate, current, and complete for the purpose at hand. Inaccurate, out-of-date and incomplete data can result in unnecessary waste and cost, as well as weaken client relationships.
- Validated data is data that’s integrated, that is, it meets logical and structural requirements for processing and analysis purposes: postal codes and phone numbers have the correct number and type of characters for the relevant location, prior purchases are correctly associated with customers, etc. Data that doesn’t meet these requirements may be excluded from analysis or other use, resulting in higher costs and lost insights.
- Privacy compliance requirements ensure that consumer preferences around the storage and use of their personal data meets their expectations. Missing this mark can result in considerable monetary and reputational risk.

But Even Good, Quality Data Isn’t Enough
Now that the data is clean, it needs context. Without context, no matter how clean and aligned the dataset may be, it’s much harder to identify actionable insights for use in everything from customer acquisition and retention to product enhancement, revenue optimization and more.
How Adding Real-Time Behavioral Data Adds Context To Datasets And Ensures Results
Context is a product of real data generated by real consumers in their online activities, such as sharing a video, downloading a brochure, or searching for recipes, flights or event tickets, etc.
Real behavioral and interest data is deterministic because it’s representative of recent, real online interactions and interests. It’s authentic, powerful, and can be made available in real-time. Think of it as ‘farm to table’ data, with less risk of over-processing it or applying faulty or unnecessary layers of data science or modeling. Just the real thing, in real-time, visualized and full of actionable insights. As a result, it can be predictive of emerging consumer trends and changing buyer preferences.
Data science will always be applied in the data industry. The opportunity is to apply that science to real data rather than to data that’s already been modeled in some way. Applying data science that’s already been modeled can dilute the original data’s authenticity and value.
Perhaps Steven Casey said it best in his team’s 2019 Forrester report: Businesses should “pay more attention to what your prospects do than to what they say” [emphasis added]. Real behavioral and interest data help teams do exactly that.
In a world that’s already crowded with data, the opportunity is to reveal the hidden value. Adding layer upon layer of analysis, modeling and other data science can obscure or weaken that value.



