
Los datos están literalmente en todas partes, y cada vez más. Para citar CloverDXEn 2021 se crearán 74 zettabytes de datos. Eso es más que 59 zettabytes en 2020 y 41 zettabytes en 2019". Para ponerlo en contexto, considere que un zettabyte es un billón de gigabytes, lo que llenaría casi 2 mil millones de iPhones de 512 GB.
¿De dónde vienen todos estos datos?
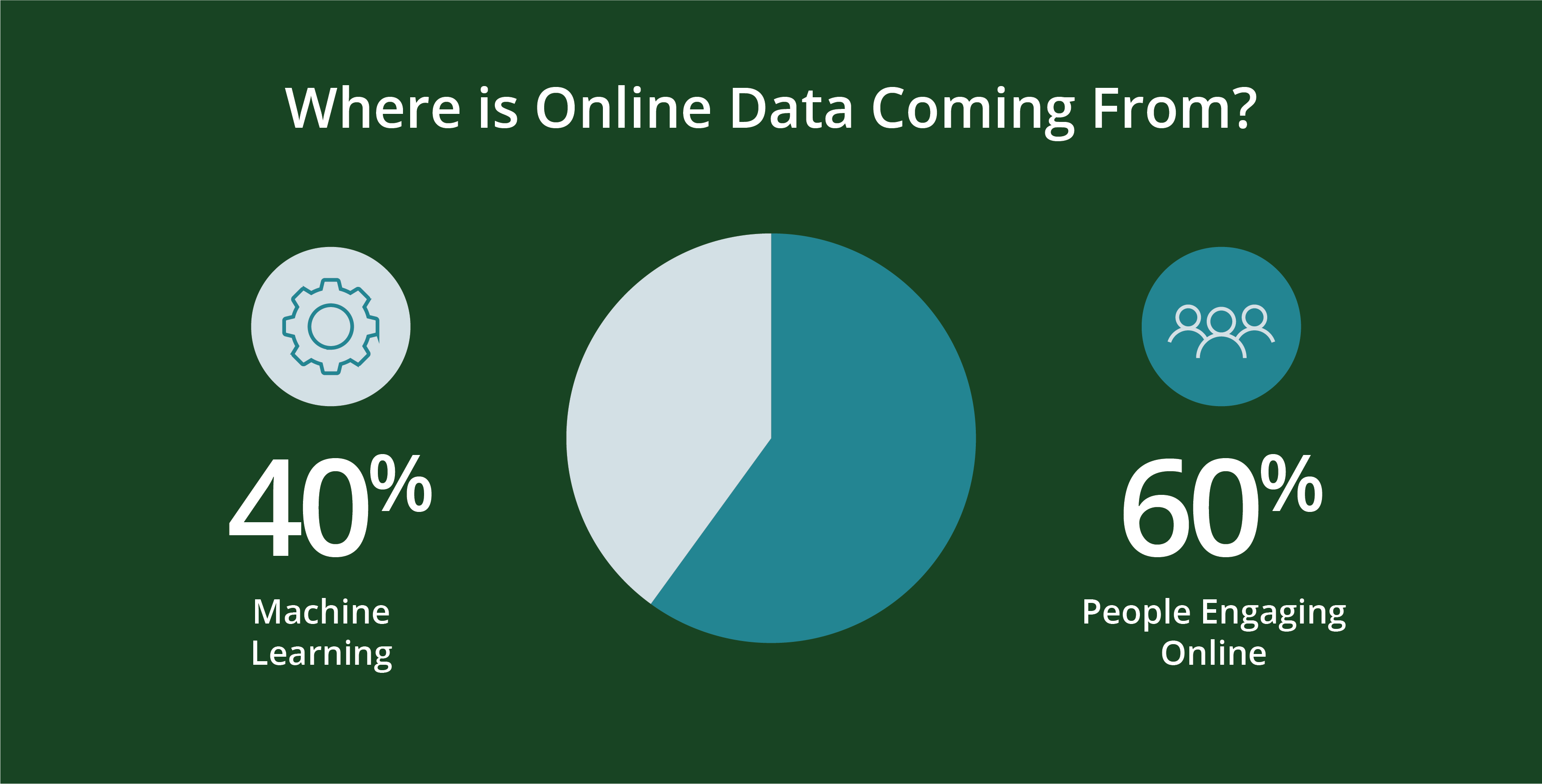
Las personas -y la programación que crean- generan datos. Más concretamente, aproximadamente el 60 por ciento de los datos en línea actuales son generados por personasEl 40 por ciento restante es generado por la máquina en scripts como registros web, APIs, puntos finales de seguridad, colas de mensajes y datos de sensores.
Considere que poco más de la mitad de la población mundial es digitalmente activa-es decir, casi 5.000 millones de personas. Por supuesto, la vida digital ha penetrado en distintas partes del mundo a ritmos diferentes. Mientras que el 90% de los norteamericanos y europeos son activos digitalmente, otras zonas están creciendo a un ritmo fenomenal, como África, que ha aumentado un 12.441% desde 2000 hasta 2020. Los nuevos usuarios de Internet en 2020 fueron 319 millones, y está creciendo a un 7% o casi un millón de nuevos usuarios cada día. A mayor número de personas, mayor actividad de búsqueda. Google, que posee el 91,9% del mercado de las búsquedas en Internet y procesa 8.500 millones de búsquedas al día. Eso es más que 5.600 millones de euros en 2021 y aproximadamente 99.000 búsquedas por segundo. ¡Hablando de crecimiento de datos!
Por eso hay tantos proveedores de datos
Las empresas necesitan proveedores de datos. Todos estos datos existen en diferentes formatos y ubicaciones. Algunos de ellos pueden combinarse de forma segura y rentable con un modesto esfuerzo. Otros requieren más. Pero en general, todos los datos deben estar "limpios" y estructurados. De este modo, pueden combinarse con otras fuentes de datos complementarias para su análisis y, a continuación, visualizarse para actuar. Este es el trabajo de los proveedores de datos.
Y como hay muchas fuentes y tipos de datos útiles para las empresas, también hay muchas formas de hacer que esos datos sean útiles. Esto puede dificultar la comparación de diferentes proveedores y servicios de un proyecto a otro. Cada proyecto se centra en diferentes resultados, industrias, tipos de clientes, etc., y cada proveedor de datos no puede ajustarse perfectamente a todos los parámetros. Más allá de las variantes de los datos, también existen diferentes metodologías -a menudo propias- que pueden dificultar la comparación.
Por supuesto, los proveedores de datos tampoco son iguales. Con tantos datos disponibles, muchos de ellos no son valiosos, o no tienen una fuente sólida, o se agregan con ciencia de datos de baja calidad. Estos factores pueden afectar al rendimiento y al valor real de los datos. Tener en cuenta estos y otros factores clave puede ayudar a garantizar una colaboración beneficiosa para todos.

Por qué manipular los datos no siempre es malo
Todos los datos se manipulan. Deben serlo, para ser utilizables. Por ejemplo, puede que se clasifiquen en orden alfabético, o en un orden basado en códigos postales o en el uso previo de productos. Tal vez se manipulen para adaptarse a los protocolos de gestión del sitio web centrados en los registros web o en la seguridad de la identificación del cliente.
Este tipo de manipulación hace que los datos sean útiles para las empresas y permite combinarlos, analizarlos y, en última instancia, visualizarlos. Pero, ¿cuánta manipulación es buena y cuánta es demasiada?
Los grandes conjuntos de datos ofrecen a las empresas una gama más amplia de datos, lo que puede garantizar que las conclusiones sean representativas de un conjunto de público digno del mercado. Sin embargo, la combinación de conjuntos de datos también debe tener en cuenta numerosos factores, desde las características de la empresa y los plazos hasta la alineación de las categorías de datos para garantizar que las conclusiones tengan el alcance y la escala deseados.
Los grandes conjuntos de datos también pueden volverse poco manejables, lo que refleja los desafíos de identificar ideas específicas y procesables que a menudo son más evidentes con pequeños subconjuntos de datos, pero que aún requieren la escala y la coherencia del conjunto de datos más grande y rico para validar los resultados.
De hecho, las manipulaciones de datos más importantes tienen que ver con la cantidad y la calidad, y son necesarias.
Los ingredientes de los buenos datos: verificados, validados y respetuosos con la privacidad
Gran parte de las manipulaciones estándar que las empresas aplican a los datos tienen que ver con calidadque tiene tres grandes factores: validación, verificación y privacidad.
- La verificación garantiza que los registros de datos están asociados a personas reales, y no a bots, y que son precisos, actuales y completos para el propósito que se persigue. Los datos inexactos, desactualizados e incompletos pueden generar gastos y desperdicios innecesarios, además de debilitar las relaciones con los clientes.
- Los datosvalidados son datos integrados, es decir, que cumplen los requisitos lógicos y estructurales para su procesamiento y análisis: los códigos postales y los números de teléfono tienen el número y el tipo de caracteres correctos para la ubicación correspondiente, las compras anteriores están correctamente asociadas a los clientes, etc. Los datos que no cumplen estos requisitos pueden quedar excluidos del análisis o de cualquier otro uso, lo que se traduce en mayores costes y pérdida de información.
- Los requisitos decumplimiento de la privacidad garantizan que las preferencias de los consumidores en torno al almacenamiento y el uso de sus datos personales satisfagan sus expectativas. No cumplir con este requisito puede suponer un riesgo monetario y de reputación considerable.

Pero ni siquiera los datos buenos y de calidad son suficientes
Ahora que los datos están limpios, necesitan contexto. Sin contexto, por muy limpio y alineado que esté el conjunto de datos, es mucho más difícil identificar las ideas procesables para su uso en todo, desde la adquisición y retención de clientes hasta la mejora de productos, la optimización de los ingresos y mucho más.
Cómo añadir datos de comportamiento en tiempo real para contextualizar los conjuntos de datos y garantizar los resultados
El contexto es un producto de datos reales generados por consumidores reales en sus actividades en línea, como compartir un vídeo, descargar un folleto o buscar recetas, vuelos o entradas para eventos, etc.
Los datos de comportamiento e intereses reales son deterministas porque son representativos de interacciones e intereses en línea recientes y reales. Son auténticos, potentes y pueden estar disponibles en tiempo real. Piense en ellos como datos "de la granja a la mesa", con menos riesgo de sobreprocesamiento o de aplicación de capas defectuosas o innecesarias de ciencia de datos o de modelización. Sólo los datos reales, en tiempo real, visualizados y llenos de información procesable. Como resultado, puede predecir las tendencias emergentes de los consumidores y los cambios en las preferencias de los compradores.
La ciencia de los datos siempre se aplicará en la industria de los datos. La oportunidad es aplicar esa ciencia a datos reales en lugar de a datos que ya han sido modelados de alguna manera. Aplicar la ciencia de datos que ya ha sido modelada puede diluir la autenticidad y el valor de los datos originales.
Tal vez Steven Casey lo dijo mejor en el informe de su equipo Informe Forrester 2019: Las empresas deben "prestar más atención a lo que hacen sus clientes potenciales que a lo que dicen" [énfasis añadido]. Los datos reales de comportamiento e intereses ayudan a los equipos a hacer exactamente eso.
En un mundo que ya está abarrotado de datos, la oportunidad es revelar el valor oculto. Añadir capa tras capa de análisis, modelización y otras ciencias de los datos puede oscurecer o debilitar ese valor.



