
データは文字通りあらゆるところに存在し、しかも増え続けている。引用すると クローバーDX, 「2021年には74ゼタバイトのデータが作成される。2020年の59ゼタバイト、2019年の41ゼタバイトから増加します。"このことを考えるには、1ゼタバイトが1兆ギガバイトで、512GBのiPhoneを20億台近く埋めることができることを考慮する必要があります。
このデータはどこから来ているのか?
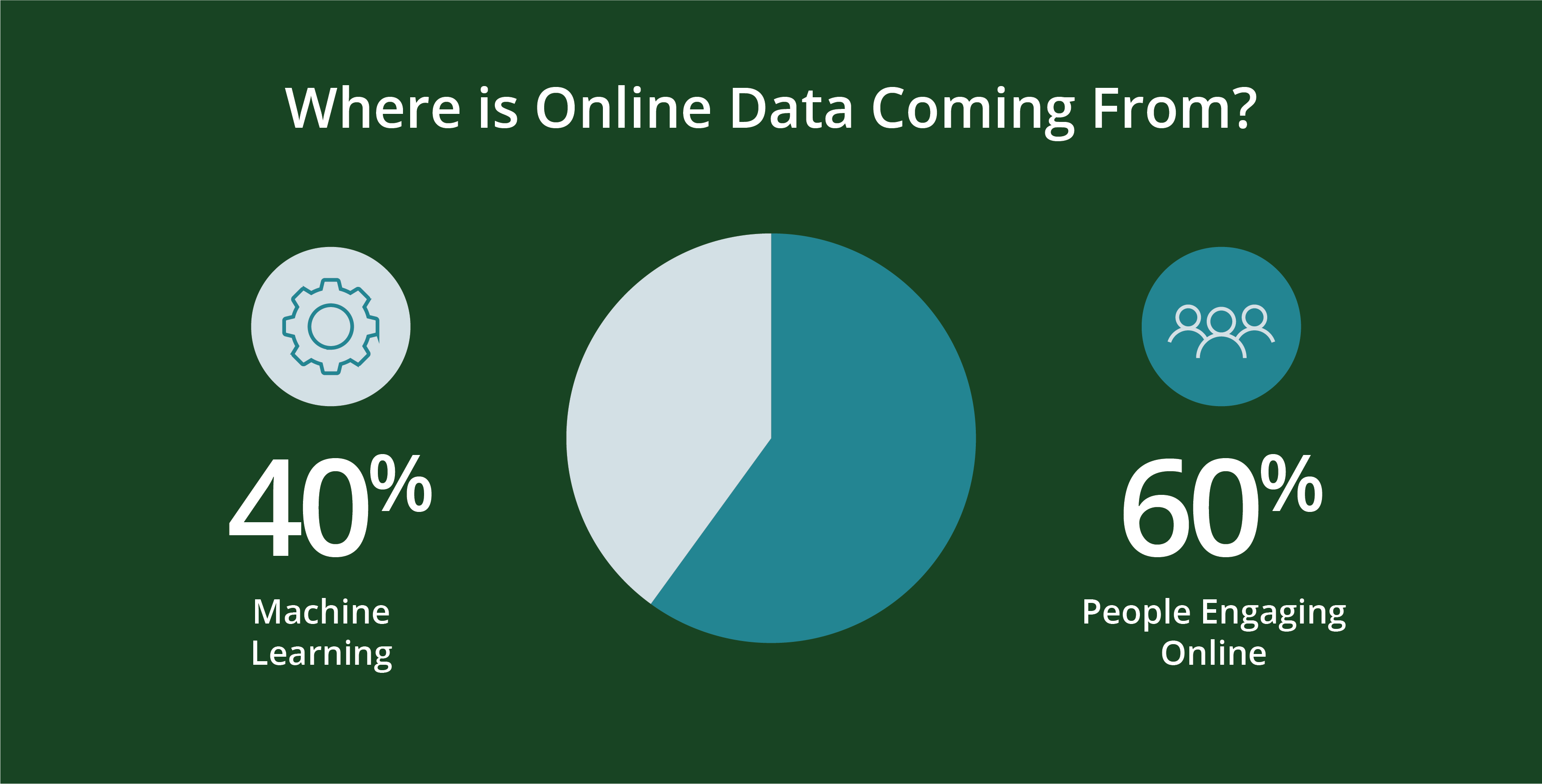
人と、人が作る番組が、データを生み出す。具体的には 今日のオンラインデータの約60%は、人によって生成されています。残りの40%は、ウェブログ、API、セキュリティエンドポイント、メッセージキュー、センサーデータなどのスクリプトで機械的に生成されたものです。
を超えることを考慮してください。 世界人口の半分がデジタル活動をしている-それは約50億人の人々です。もちろん、デジタルライフは世界のさまざまな地域に、さまざまな速度で浸透しています。北米とヨーロッパでは90%がデジタルライフを楽しんでいますが、その他の地域では驚異的な成長を遂げています。例えば、アフリカでは2000年から2020年にかけて12,441%も増加しています。2020年の新規インターネットユーザーは3億1,900万人で、7%、つまり毎日100万人近くが新たに増加しています。人々が増えれば、検索活動も活発になります。Googleは インターネット検索市場の91.9%を所有し、1日あたり85億回の検索を処理する。.から増加しています。 2021年に56億円 と、およそ 毎秒99,000回の検索数.データ増加の話!
データプロバイダーが多い理由
企業にはデータプロバイダーが必要です。これらのデータはすべて、さまざまな形式と場所に存在します。その中には、わずかな努力で安全かつ有益に組み合わせることができるものもあります。しかし、もっと多くの労力を必要とするものもあります。しかし、一般的には、すべてのデータは「クリーン」で構造化されている必要があります。そうすれば、他の補完的なデータソースと組み合わせて分析し、視覚化して行動を起こすことができる。これはデータプロバイダーの仕事である。
また、ビジネスにとって有用なデータのソースや種類が多いため、そのデータを有効に活用する方法も多岐にわたります。そのため、プロジェクトごとに異なるベンダーやサービスを比較することが難しい場合があります。プロジェクトごとに注力する成果、業界、顧客のタイプなどが異なり、各データプロバイダーがすべてのパラメータに完璧に適合できるわけではありません。また、データの多様性だけでなく、多くの場合、独自の方法論も存在するため、比較が困難な場合があります。
もちろん、データプロバイダーも一様ではありません。多くのデータが利用可能ですが、その多くは価値がなかったり、適切な情報源でなかったり、低級なデータサイエンスで集計されたりしています。これらの要因は、パフォーマンスやデータの実際の価値に影響を与える可能性があります。これらの要因やその他のいくつかの重要な要因を念頭に置くことで、Win-Winのコラボレーションを実現することができます。

データを操作することが必ずしも悪いことではない理由
すべてのデータは操作される。使えるようにするためには、そうしなければなりません。例えば、アルファベット順に並べたり、郵便番号や製品の使用歴に基づいて並べたり。また、ウェブログや顧客IDのセキュリティに焦点を当てたウェブサイト管理プロトコルに適合するように操作されるかもしれません。
このような操作を行うことで、企業にとって有用なデータとなり、データを組み合わせ、分析し、最終的に可視化することができるようになるのです。しかし、どの程度の操作が良くて、どの程度の操作が過剰なのでしょうか?
大規模なデータセットにより、企業はより広範なデータを得ることができ、結論が市場価値のある聴衆を代表していることを確認することができる。しかし、データセットを組み合わせるには、企業統計やタイムラインからデータカテゴリーの整合性まで、多くの要因を考慮し、結論が望ましい範囲と規模を満たすようにする必要があります。
大規模なデータセットが扱いにくくなることもあります。これは、特定の実用的な洞察を特定するという課題を反映したもので、小規模なデータセットでは明らかになりやすいものの、結果を検証するには、より大規模で豊富なデータセットの規模と一貫性を必要とします。
実は、データ操作の中で最も重要なのは、量と質に関わることであり、それは必要なことなのです。
優れたデータの構成要素-検証済み、妥当性確認済み、プライバシー準拠
企業がデータに施す標準的な操作の多くは、次のようなものと関係がある。 クオリティは、「検証」「信頼性」「プライバシー」という3つの大きな要素で構成されています。
- 検証は、データレコードがボットではなく実在の人物に関連付けられ、正確で最新かつ完全なものであることを確認するものです。不正確なデータ、古いデータ、不完全なデータは、不必要な無駄とコストを生み、顧客との関係を弱めることにもなりかねません。
- 検証済み データとは、統合されたデータ、つまり、処理や分析のために必要な論理的・構造的要件を満たしたデータのことで、郵便番号や電話番号は該当する場所の正しい文字数・文字種である、過去の購入品が正しく顧客に関連付けられる、などです。このような要件を満たさないデータは、分析やその他の用途から除外される可能性があり、結果としてコスト増と洞察力の喪失を招きます。
- 個人情報保護に関するコンプライアンス 要件は、個人データの保存と使用に関する消費者の希望がその期待に沿うものであることを保証します。このマークを見逃すと、かなりの金銭的リスクと風評リスクが生じます。

しかし、良質なデータであっても十分ではありません。
データがきれいになったからには、コンテキストが必要です。コンテキストがなければ、データセットがどんなにクリーンで整合性が取れていても、顧客の獲得や維持、製品の強化、収益の最適化など、あらゆることに利用できる実用的なインサイトを特定することは非常に難しくなります。
リアルタイムの行動データを追加することで、データセットにコンテキストを追加し、結果を確実にする方法
コンテキストとは、実際の消費者が動画の共有、パンフレットのダウンロード、レシピや航空券、イベントチケットの検索など、オンライン活動で生成したリアルデータの産物である。
リアルな行動・関心データは、最近のリアルなオンライン上のやりとりや関心を代表するものであるため、決定論的なデータです。本物であり、強力であり、リアルタイムで利用することができます。これは「農場から食卓まで」のデータであり、過剰に処理されたり、誤った、あるいは不必要なデータサイエンスやモデリングを適用したりするリスクは少ないと考えてください。リアルタイムのデータで、可視化され、実用的な洞察に満ちているのです。その結果、新たな消費者トレンドや購買者の嗜好の変化を予測することができるのです。
データサイエンスは、データ産業において常に適用されるものです。そのチャンスは、すでに何らかの形でモデル化されたデータではなく、実際のデータにそのサイエンスを適用することです。すでにモデル化されたデータサイエンスを適用すると、元のデータの信憑性や価値が薄れてしまう可能性があります。
おそらくスティーブン・ケーシーは、チームの中で最もよく言った言葉だろう。 2019年フォレスターレポート:企業は「見込み客が 何を 言うかよりも、何を するかに もっと注意を 払う 」 べきである[強調]。実際の行動と関心データは、チームがまさにそれを行うのに役立ちます。
すでにデータで溢れかえっている世界では、隠れた価値を明らかにすることがチャンスなのです。分析、モデリング、その他のデータサイエンスを何層にも重ねると、その価値が不明瞭になったり、弱まったりすることがあります。



