
Os dados estão literalmente em todo o lado, e estão a aumentar. Para citar CloverDX"74 zettabytes de dados serão criados em 2021. Isso passa de 59 zettabytes em 2020 para 41 zettabytes em 2019". Para contextualizar isto, considere que um zettabyte é um trilião de gigabytes, que preencheria quase 2 mil milhões de iPhones de 512GB.
De onde provêm todos estes dados?
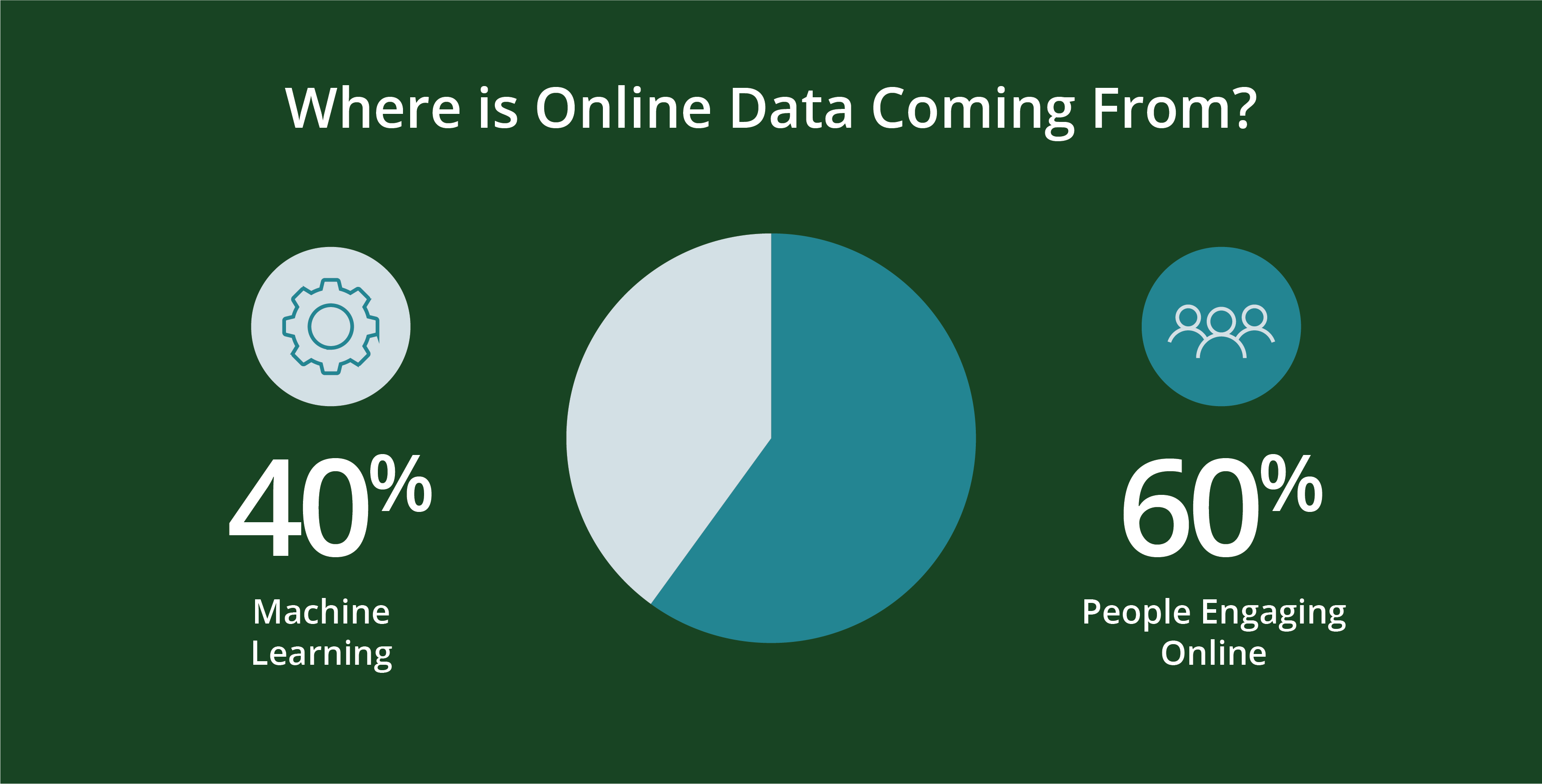
As pessoas - e a programação que elas criam - geram dados. Mais especificamente, cerca de 60 por cento dos dados online actuais são gerados por pessoascom os restantes 40% a serem gerados por máquinas em scripts como registos da web, APIs, pontos finais de segurança, filas de mensagens e dados de sensores.
Considere que pouco mais de metade da população mundial é digitalmente activa-é de quase 5 mil milhões de pessoas. É claro que a vida digital penetrou em diferentes partes do globo a ritmos diferentes. Enquanto 90% dos norte-americanos e europeus são digitalmente activos, outras áreas estão a crescer a taxas fenomenais como a África, que aumentou 12,441% de 2000 a 2020. Os novos utilizadores da Internet em 2020 totalizaram 319 milhões, e está a crescer a 7% ou quase um milhão de novos utilizadores todos os dias. Com mais pessoas vem mais actividade de pesquisa. Google, que detém 91,9% do mercado de pesquisa na Internet, processa 8,5 mil milhões de pesquisas por dia. Isso é de 5,6 mil milhões em 2021 e aproximadamente 99.000 buscas a cada segundo. Fale sobre o crescimento dos dados!
E é por isso que existem tantos fornecedores de dados
As empresas precisam de fornecedores de dados. Todos estes dados existem em diferentes formatos e locais. Alguns deles podem ser combinados de forma segura e rentável com um esforço modesto. Outros requerem mais. Mas, em geral, todos os dados devem ser "limpos" e estruturados. Dessa forma, podem ser combinados com outras fontes de dados complementares para análise e depois visualizados para acção. Este é o trabalho dos fornecedores de dados.
E como existem muitas fontes e tipos de dados úteis para as empresas, existem também muitas maneiras de tornar esses dados úteis. Isto pode tornar difícil comparar diferentes fornecedores e serviços de um projecto para outro. Cada projecto concentra-se em diferentes resultados, indústrias, tipos de clientes, etc., e cada fornecedor de dados não pode encaixar perfeitamente em cada parâmetro. Para além das variações dos dados, existem também diferentes metodologias - muitas vezes proprietárias - que podem tornar a comparação um desafio.
Naturalmente, os fornecedores de dados também não são criados de forma igual. Com tantos dados disponíveis, muitos deles não são valiosos, ou não têm uma fonte sólida, ou são agregados com dados científicos de baixa qualidade. Estes factores podem afectar o desempenho e o valor real dos dados. Mantendo estes e alguns outros factores-chave em mente, pode ajudar a assegurar uma colaboração vantajosa para todos.

Porque Manipular dados nem sempre é uma coisa má
Todos os dados são manipulados. Tem de ser, para ser utilizável. Por exemplo, talvez seja ordenado por ordem alfabética, ou uma ordem baseada em códigos postais ou utilização prévia do produto. Talvez seja manipulado para se adequar aos protocolos de gestão de sítios web, concentrando-se nos registos da web ou na segurança do clienteID.
Este tipo de manipulação torna os dados úteis às empresas, e permite que os dados sejam combinados, analisados e finalmente visualizados. Mas quanta manipulação é boa, e quanto é demasiada?
Grandes conjuntos de dados dão às empresas uma maior variedade de dados, que podem assegurar que as conclusões sejam representativas de um conjunto de público digno de mercado. No entanto, a combinação de conjuntos de dados deve também abordar numerosos factores, desde os dados firmográficos e cronológicos até ao alinhamento das categorias de dados, para assegurar que as conclusões satisfazem o âmbito e a escala desejados.
Grandes conjuntos de dados também podem tornar-se pesados, reflectindo os desafios de identificar percepções específicas e accionáveis que são frequentemente mais aparentes com pequenos subconjuntos de dados, mas que ainda requerem a escala e coerência do conjunto de dados maior e mais rico para validar os resultados.
Na realidade, as manipulações de dados mais importantes têm a ver com quantidade e qualidade - e são necessárias.
Os Ingredientes de Bons Dados - Verificado, Validado, Compatível com a Privacidade
Muitas das manipulações padrão que as empresas aplicam aos dados têm a ver com qualidadeque tem três grandes factores: validação, verificação, e privacidade.
- A verificação assegura que os registos de dados estão associados a pessoas reais, e não a bots, e que são precisos, actuais e completos para os fins em vista. Dados imprecisos, desactualizados e incompletos podem resultar em desperdício e custos desnecessários, bem como enfraquecer as relações com os clientes.
- Dadosvalidados são dados integrados, ou seja, cumprem requisitos lógicos e estruturais para efeitos de processamento e análise: os códigos postais e números de telefone têm o número e tipo correcto de caracteres para o local relevante, as compras prévias estão correctamente associadas aos clientes, etc. Os dados que não satisfazem estes requisitos podem ser excluídos da análise ou outra utilização, resultando em custos mais elevados e perda de conhecimentos.
- Os requisitos deconformidade com a privacidade asseguram que as preferências dos consumidores em torno do armazenamento e utilização dos seus dados pessoais satisfazem as suas expectativas. A falta desta marca pode resultar num risco monetário e reputacional considerável.

Mas mesmo dados bons e de qualidade não são suficientes
Agora que os dados estão limpos, é necessário um contexto. Sem contexto, por mais limpo e alinhado que o conjunto de dados possa estar, é muito mais difícil identificar ideias accionáveis para utilização em tudo, desde a aquisição e retenção de clientes até ao melhoramento de produtos, optimização de receitas e muito mais.
Como Adicionar Dados Comportamentais em Tempo Real Adiciona Contexto a Conjuntos de Dados e Assegura Resultados
O contexto é um produto de dados reais gerados por consumidores reais nas suas actividades em linha, tais como a partilha de um vídeo, o descarregamento de uma brochura, ou a procura de receitas, voos ou bilhetes para eventos, etc.
Os verdadeiros dados comportamentais e de interesse são deterministas porque são representativos de interacções e interesses recentes e reais em linha. É autêntico, poderoso, e pode ser disponibilizado em tempo real. Pense nisto como dados 'farm to table', com menos risco de processamento excessivo ou de aplicação de camadas defeituosas ou desnecessárias de ciência ou modelação de dados. Apenas o real, em tempo real, visualizado e repleto de percepções accionáveis. Como resultado, pode ser preditivo das tendências emergentes dos consumidores e da mudança das preferências dos compradores.
A ciência dos dados será sempre aplicada na indústria de dados. A oportunidade é aplicar essa ciência a dados reais e não a dados que já tenham sido modelados de alguma forma. A aplicação da ciência de dados que já foi modelada pode diluir a autenticidade e o valor dos dados originais.
Talvez Steven Casey tenha dito que o melhor na sua equipa Relatório Forrester 2019: As empresas devem "prestar mais atenção ao que as suas perspectivas fazem do que ao que dizem" [ênfase acrescentada]. Dados comportamentais e de interesse reais ajudam as equipas a fazer exactamente isso.
Num mundo que já está cheio de dados, a oportunidade é revelar o valor escondido. Adicionar camada sobre camada de análise, modelagem e outros dados científicos pode obscurecer ou enfraquecer esse valor.



