
I dati sono letteralmente ovunque, e stanno aumentando. Per citare CloverDX, "74 zettabyte di dati saranno creati nel 2021. Questo è in aumento da 59 zettabyte nel 2020 e 41 zettabyte nel 2019". Per mettere questo in contesto, considerate che uno zettabyte è un trilione di gigabyte, che riempirebbe quasi 2 miliardi di iPhone da 512GB.
Da dove vengono tutti questi dati?
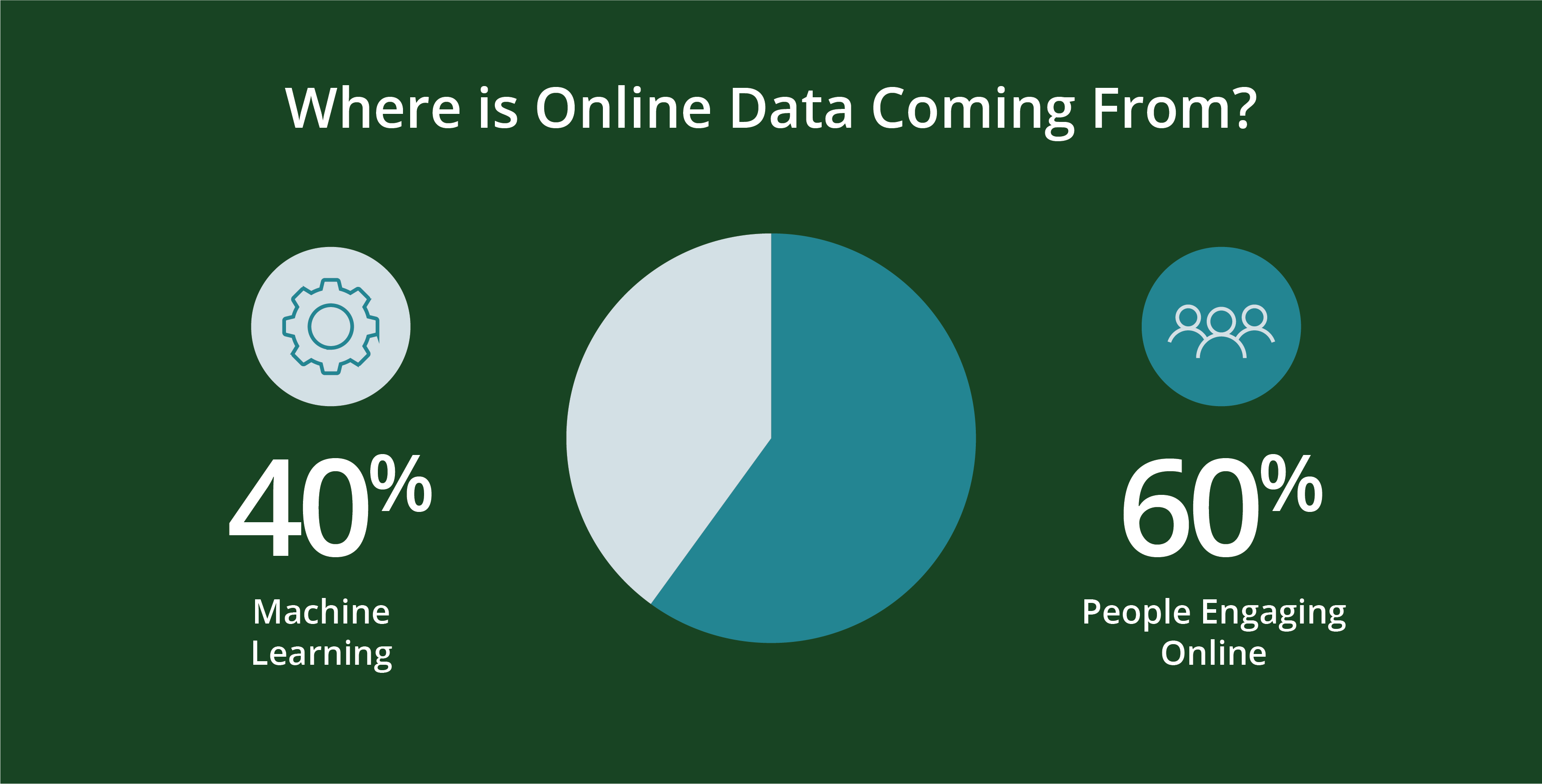
Le persone e la programmazione che creano generano dati. Più specificamente, circa il 60% dei dati online di oggi sono generati da personecon il restante 40 per cento generato dalla macchina in script come log web, API, endpoint di sicurezza, code di messaggi e dati di sensori.
Si consideri che poco più di metà della popolazione mondiale è attiva digitalmente-sono quasi 5 miliardi di persone. Naturalmente, la vita digitale è penetrata in diverse parti del mondo a tassi diversi. Mentre il 90% dei nordamericani e degli europei sono attivi digitalmente, altre aree stanno crescendo a tassi fenomenali, come l'Africa, che è in crescita del 12.441% dal 2000 al 2020. I nuovi utenti internet nel 2020 sono stati 319 milioni, e sta crescendo del 7% o quasi un milione di nuovi utenti ogni giorno. Con più persone arriva più attività di ricerca. Google, che possiede il 91,9% del mercato della ricerca su internet, elabora 8,5 miliardi di ricerche al giorno. Questo è in aumento rispetto a 5,6 miliardi nel 2021 e approssimativamente 99.000 ricerche ogni secondo. A proposito di crescita dei dati!
Ecco perché ci sono così tanti fornitori di dati
Le aziende hanno bisogno di fornitori di dati. Tutti questi dati esistono in diversi formati e luoghi. Alcuni di essi possono essere combinati in modo sicuro e redditizio con uno sforzo modesto. Altri richiedono di più. Ma in generale, tutti i dati devono essere "puliti" e strutturati. In questo modo possono essere combinati con altre fonti di dati complementari per l'analisi e poi visualizzati per l'azione. Questo è il lavoro dei fornitori di dati.
E poiché ci sono molte fonti e tipi di dati utili per le aziende, ci sono anche molti modi per rendere quei dati utili. Questo può rendere difficile confrontare diversi fornitori e servizi da un progetto all'altro. Ogni progetto si concentra su risultati diversi, industrie, tipi di clienti, ecc. e ogni fornitore di dati non può adattarsi perfettamente ad ogni parametro. Oltre alle variabilità dei dati, ci sono anche diverse metodologie, spesso proprietarie, che possono rendere difficile il confronto.
Naturalmente, anche i fornitori di dati non sono creati uguali. Con così tanti dati disponibili, molti di essi non sono di valore, o non provengono da fonti solide, o sono aggregati con una scienza dei dati di bassa qualità. Questi fattori possono influenzare le prestazioni e il valore effettivo dei dati. Tenere a mente questi e alcuni altri fattori chiave può aiutare a garantire una collaborazione vincente.

Perché manipolare i dati non è sempre una brutta cosa
Tutti i dati sono manipolati. Devono esserlo, per essere utilizzabili. Per esempio, forse sono ordinati in ordine alfabetico, o in base al codice postale o all'uso precedente del prodotto. Forse sono manipolati per adattarsi ai protocolli di gestione dei siti web che si concentrano sui registri web o sulla sicurezza del customerID.
Questo tipo di manipolazione rende i dati utili alle aziende e permette di combinare, analizzare e infine visualizzare i dati. Ma quanta manipolazione è buona e quanta è troppa?
Gli insiemi di dati di grandi dimensioni danno alle aziende una gamma più ampia di dati, il che può garantire che le conclusioni siano rappresentative di un insieme di pubblico degno del mercato. Tuttavia, la combinazione di serie di dati deve anche affrontare numerosi fattori, dai dati socio-culturali e temporali all'allineamento delle categorie di dati per garantire che le conclusioni soddisfino la portata e la scala desiderata.
I grandi set di dati possono anche diventare ingombranti, riflettendo le sfide di identificare intuizioni specifiche e utilizzabili che sono spesso più evidenti con piccoli sottoinsiemi di dati, ma richiedono comunque la scala e la coerenza del più grande e ricco set di dati per validare i risultati.
Infatti, le manipolazioni di dati più importanti hanno a che fare con la quantità e la qualità, e sono necessarie.
Gli ingredienti di buoni dati: verificati, convalidati, conformi alla privacy
Molte delle manipolazioni standard che le aziende applicano ai dati hanno a che fare con qualitàche ha tre grandi fattori: convalida, verifica e privacy.
- Laverifica assicura che i record di dati siano associati a persone reali, e non a bot, e che siano accurati, aggiornati e completi per lo scopo in questione. Dati imprecisi, non aggiornati e incompleti possono provocare inutili sprechi e costi, oltre a indebolire le relazioni con i clienti.
- I daticonvalidati sono dati integrati, cioè che soddisfano i requisiti logici e strutturali per l'elaborazione e l'analisi: i codici postali e i numeri di telefono hanno il numero e il tipo di caratteri corretti per la località interessata, gli acquisti precedenti sono associati correttamente ai clienti, ecc. I dati che non soddisfano questi requisiti possono essere esclusi dall'analisi o da altri usi, con conseguenti costi più elevati e perdite di informazioni.
- I requisitidi conformità alla privacy assicurano che le preferenze dei consumatori circa l'archiviazione e l'uso dei loro dati personali soddisfino le loro aspettative. Mancare questo marchio può comportare un considerevole rischio monetario e di reputazione.

Ma anche i dati buoni e di qualità non bastano
Ora che i dati sono puliti, hanno bisogno di un contesto. Senza contesto, non importa quanto pulito e allineato possa essere il set di dati, è molto più difficile identificare intuizioni utilizzabili per l'uso in tutto, dall'acquisizione e conservazione dei clienti al miglioramento dei prodotti, all'ottimizzazione delle entrate e altro.
Come l'aggiunta di dati comportamentali in tempo reale aggiunge contesto ai set di dati e garantisce i risultati
Il contesto è un prodotto di dati reali generati da consumatori reali nelle loro attività online, come condividere un video, scaricare una brochure, o cercare ricette, voli o biglietti per eventi, ecc.
I dati comportamentali e di interesse reali sono determinanti perché sono rappresentativi di interazioni e interessi online recenti e reali. Sono autentici, potenti e possono essere resi disponibili in tempo reale. Pensate ai dati "dalla fattoria alla tavola", con meno rischi di sovraelaborazione o di applicazione di strati errati o inutili di scienza dei dati o modellazione. Solo la cosa reale, in tempo reale, visualizzata e piena di intuizioni utilizzabili. Come risultato, può essere predittivo delle tendenze emergenti dei consumatori e del cambiamento delle preferenze degli acquirenti.
La scienza dei dati sarà sempre applicata nell'industria dei dati. L'opportunità è quella di applicare quella scienza ai dati reali piuttosto che ai dati che sono già stati modellati in qualche modo. Applicare la scienza dei dati che è già stata modellata può diluire l'autenticità e il valore dei dati originali.
Forse Steven Casey l'ha detto meglio nel suo Rapporto Forrester 2019: Le aziende dovrebbero "prestare più attenzione a ciò che fannoi vostri potenziali clienti che a ciò che dicono" [enfasi aggiunta]. I dati comportamentali e di interesse reali aiutano i team a fare esattamente questo.
In un mondo che è già affollato di dati, l'opportunità è quella di rivelare il valore nascosto. Aggiungere strati su strati di analisi, modellazione e altre scienze dei dati può oscurare o indebolire quel valore.



