
Les données sont littéralement partout, et elles ne cessent d'augmenter. Pour citer CloverDX"74 zettaoctets de données seront créés en 2021. C'est une augmentation par rapport aux 59 zettaoctets de 2020 et aux 41 zettaoctets de 2019." Pour mettre cela en contexte, considérez qu'un zettaoctet correspond à un trillion de gigaoctets, ce qui remplirait près de 2 milliards d'iPhones de 512 Go.
D'où viennent toutes ces données ?
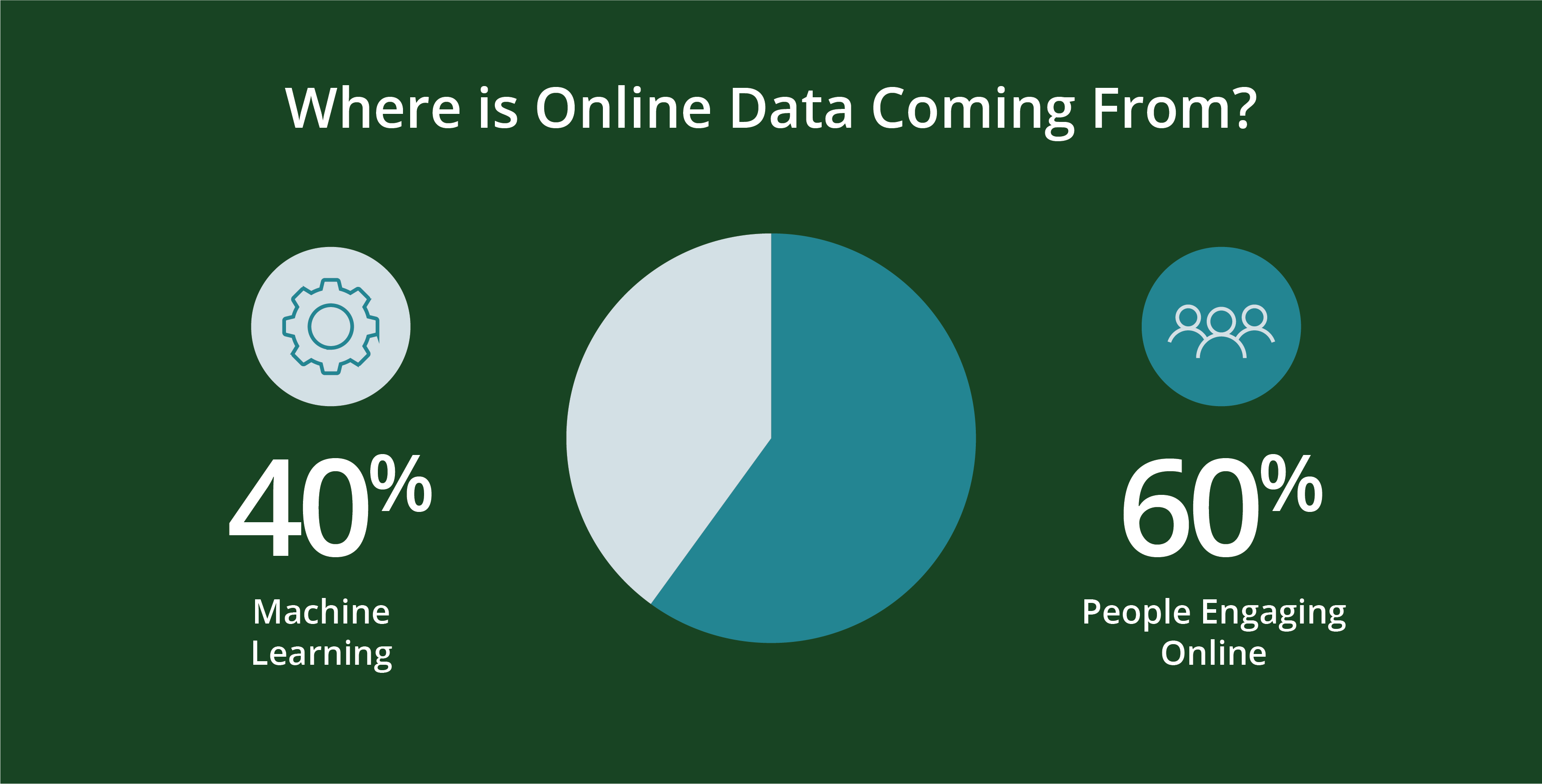
Les gens - et les programmes qu'ils créent - génèrent des données. Plus précisément, Environ 60 % des données en ligne actuelles sont générées par des personnes.Les 40 % restants sont générés par des machines dans des scripts tels que les journaux Web, les API, les points de terminaison de sécurité, les files d'attente de messages et les données des capteurs.
Considérez qu'un peu plus de la moitié de la population mondiale est numériquement active-soit près de 5 milliards de personnes. Bien entendu, la vie numérique a pénétré différentes parties du globe à des rythmes différents. Si 90 % des Nord-Américains et des Européens sont actifs sur le plan numérique, d'autres régions connaissent une croissance phénoménale, comme l'Afrique, dont le nombre d'utilisateurs a augmenté de 12 441 % entre 2000 et 2020. En 2020, le nombre de nouveaux utilisateurs de l'internet s'élevait à 319 millions, et la croissance est de 7 %, soit près d'un million de nouveaux utilisateurs par jour. L'augmentation du nombre de personnes s'accompagne d'une augmentation des activités de recherche. Google, qui détient 91,9 % du marché de la recherche sur Internet et traite 8,5 milliards de recherches par jour.. C'est une augmentation par rapport à 5,6 milliards d'euros en 2021 et en gros 99 000 recherches par seconde. Vous parlez d'une croissance des données !
C'est pourquoi il y a tant de fournisseurs de données.
Les entreprises ont besoin de fournisseurs de données. Toutes ces données existent sous différents formats et à différents endroits. Certaines d'entre elles peuvent être combinées de manière sûre et rentable avec un effort modeste. D'autres exigent davantage. Mais en général, toutes les données doivent être "propres" et structurées. De cette façon, elles peuvent être combinées avec d'autres sources de données complémentaires pour être analysées, puis visualisées pour être utilisées. C'est le travail des fournisseurs de données.
Et parce qu'il existe de nombreuses sources et types de données utiles aux entreprises, il existe également de nombreuses façons de rendre ces données utiles. Il peut donc être difficile de comparer les différents fournisseurs et services d'un projet à l'autre. Chaque projet se concentre sur des résultats, des industries, des types de clients, etc. différents, et chaque fournisseur de données ne peut pas répondre parfaitement à tous les paramètres. Au-delà de la variabilité des données, il existe également différentes méthodologies - souvent propriétaires - qui peuvent rendre la comparaison difficile.
Bien sûr, les fournisseurs de données ne sont pas tous égaux. Avec la quantité de données disponibles, une grande partie d'entre elles n'a pas de valeur, n'est pas bien sourcée ou est agrégée avec une science des données de qualité inférieure. Ces facteurs peuvent affecter les performances et la valeur réelle des données. En gardant à l'esprit ces facteurs et quelques autres facteurs clés, vous pouvez garantir une collaboration gagnant-gagnant.

Pourquoi manipuler les données n'est pas toujours une mauvaise chose
Toutes les données sont manipulées. Elles doivent l'être pour être utilisables. Par exemple, elles peuvent être triées par ordre alphabétique, ou par ordre basé sur le code postal ou l'utilisation antérieure d'un produit. Elles sont peut-être manipulées pour s'adapter aux protocoles de gestion des sites Web axés sur les journaux Web ou la sécurité des identifiants des clients.
Ce type de manipulation rend les données utiles aux entreprises, et permet de les combiner, de les analyser et finalement de les visualiser. Mais quelle quantité de manipulation est bonne, et quelle quantité est excessive ?
Les grands ensembles de données donnent aux entreprises des gammes de données plus larges, ce qui peut garantir que les conclusions sont représentatives d'un ensemble d'audience digne du marché. Cependant, la combinaison d'ensembles de données doit également tenir compte de nombreux facteurs, allant des données géographiques et temporelles à l'alignement des catégories de données, afin de garantir que les conclusions répondent à la portée et à l'échelle souhaitées.
Les grands ensembles de données peuvent également devenir difficiles à manier, car il est difficile d'identifier des informations spécifiques et exploitables qui sont souvent plus évidentes avec de petits sous-ensembles de données, mais qui nécessitent néanmoins l'échelle et la cohérence d'un ensemble de données plus grand et plus riche pour valider les résultats.
En fait, les manipulations de données les plus importantes ont trait à la quantité et à la qualité - et elles sont nécessaires.
Les ingrédients de bonnes données - vérifiées, validées, conformes à la confidentialité
La plupart des manipulations standard que les entreprises appliquent aux données concernent qualitéqui comporte trois grands facteurs : la validation, la vérification et la confidentialité.
- Lavérification permet de s'assurer que les enregistrements de données sont associés à des personnes réelles, et non à des robots, et qu'ils sont exacts, à jour et complets pour l'objectif visé. Des données inexactes, périmées et incomplètes peuvent entraîner des gaspillages et des coûts inutiles, ainsi qu'affaiblir les relations avec les clients.
- Les donnéesvalidées sont des données intégrées, c'est-à-dire qu'elles répondent à des exigences logiques et structurelles à des fins de traitement et d'analyse : les codes postaux et les numéros de téléphone comportent le nombre et le type de caractères corrects pour le lieu concerné, les achats antérieurs sont correctement associés aux clients, etc. Les données qui ne satisfont pas à ces exigences peuvent être exclues de l'analyse ou d'autres utilisations, ce qui entraîne des coûts plus élevés et une perte d'informations.
- Les exigences deconformité en matière de protection de la vie privée garantissent que les préférences des consommateurs en matière de stockage et d'utilisation de leurs données personnelles répondent à leurs attentes. Manquer ce point peut entraîner un risque monétaire et de réputation considérable.

Mais même des données de bonne qualité ne suffisent pas
Maintenant que les données sont propres, elles ont besoin de contexte. Sans contexte, aussi propre et aligné que soit l'ensemble de données, il est beaucoup plus difficile d'identifier des informations exploitables pour l'acquisition et la fidélisation des clients, l'amélioration des produits, l'optimisation des revenus, etc.
Comment l'ajout de données comportementales en temps réel ajoute du contexte aux ensembles de données et garantit des résultats
Le contexte est le produit de données réelles générées par de vrais consommateurs dans le cadre de leurs activités en ligne, comme le partage d'une vidéo, le téléchargement d'une brochure ou la recherche de recettes, de vols ou de billets pour un événement, etc.
Les données réelles de comportement et d'intérêt sont déterministes car elles sont représentatives d'interactions et d'intérêts en ligne récents et réels. Elles sont authentiques, puissantes et peuvent être mises à disposition en temps réel. Pensez-y comme à des données "de la ferme à la table", avec moins de risque de les surtraiter ou d'appliquer des couches erronées ou inutiles de science des données ou de modélisation. Il s'agit simplement de données réelles, en temps réel, visualisées et riches en informations exploitables. Elles peuvent donc être prédictives des nouvelles tendances de consommation et de l'évolution des préférences des acheteurs.
La science des données sera toujours appliquée dans l'industrie des données. L'opportunité est d'appliquer cette science à des données réelles plutôt qu'à des données qui ont déjà été modélisées d'une manière ou d'une autre. L'application de la science des données qui a déjà été modélisée peut diluer l'authenticité et la valeur des données d'origine.
Peut-être que Steven Casey l'a mieux exprimé dans le discours de son équipe. Rapport Forrester 2019: Les entreprises devraient "accorder plus d'attention à ce que vos prospects font qu'à ce qu'ils disent" [c'est nous qui soulignons]. Les données réelles sur le comportement et les intérêts aident les équipes à faire exactement cela.
Dans un monde déjà encombré de données, l'opportunité est de révéler la valeur cachée. L'ajout de couches successives d'analyses, de modélisations et autres sciences des données peut masquer ou affaiblir cette valeur.



