
Daten sind buchstäblich überall, und sie werden immer mehr. Um zu zitieren CloverDX"Im Jahr 2021 werden 74 Zettabyte an Daten erzeugt werden. Das ist ein Anstieg gegenüber 59 Zettabyte im Jahr 2020 und 41 Zettabyte im Jahr 2019." Zum Vergleich: Ein Zettabyte entspricht einer Billion Gigabyte, was fast 2 Milliarden 512-GB-iPhones füllen würde.
Woher kommen all diese Daten?
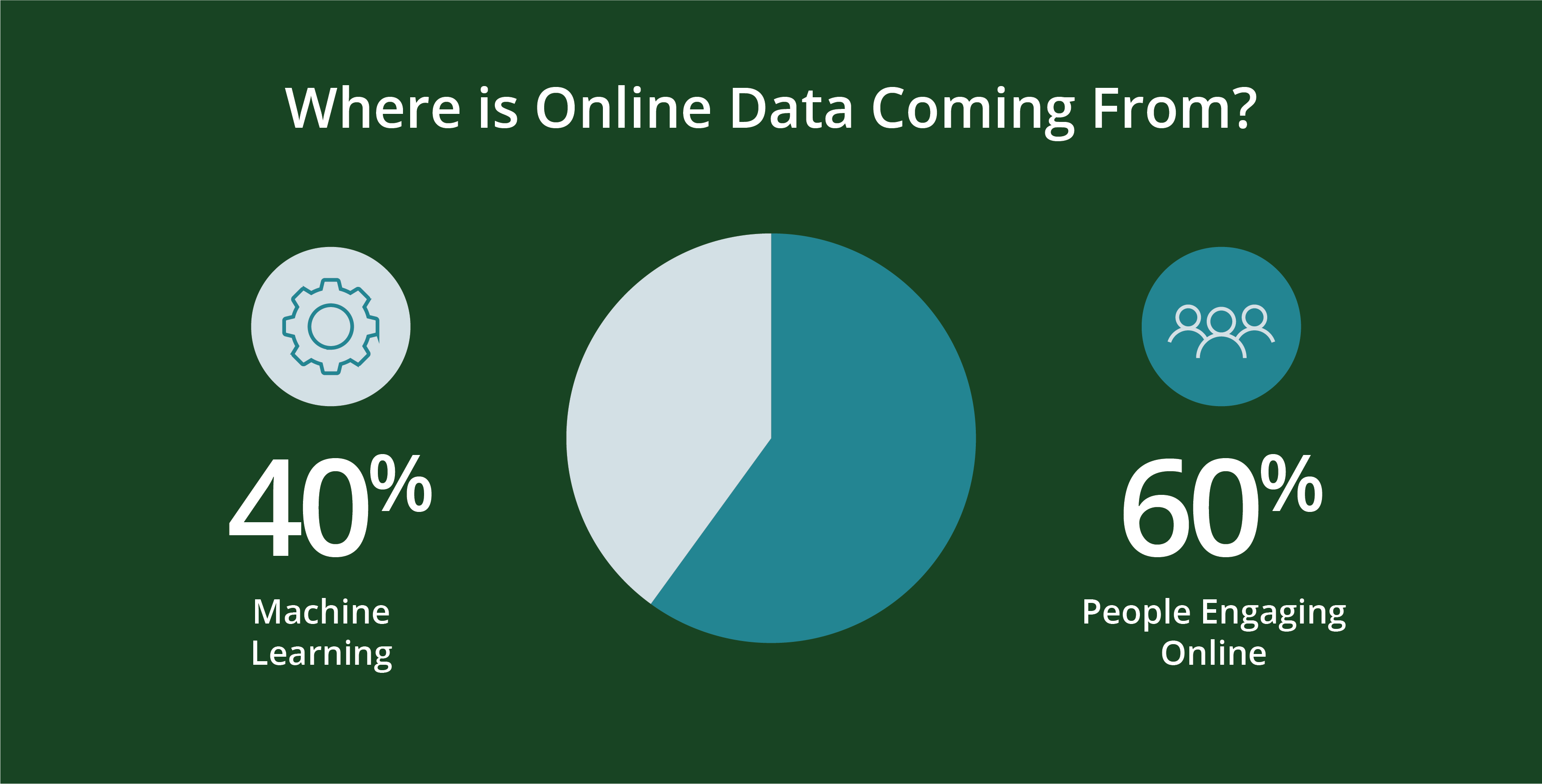
Menschen - und die von ihnen erstellten Programme - erzeugen Daten. Genauer gesagt, rund 60 Prozent der heutigen Online-Daten werden von Menschen erzeugtDie restlichen 40 Prozent werden maschinell in Skripten wie Webprotokollen, APIs, Sicherheitsendpunkten, Nachrichtenwarteschlangen und Sensordaten generiert.
Bedenken Sie, dass knapp über die Hälfte der Weltbevölkerung ist digital aktiv-das sind fast 5 Milliarden Menschen. Natürlich hat das digitale Leben die verschiedenen Teile der Welt in unterschiedlichem Tempo durchdrungen. Während 90 % der Nordamerikaner und Europäer digital aktiv sind, wachsen andere Regionen mit phänomenalen Raten - wie Afrika, wo die Zahl der Internetnutzer zwischen 2000 und 2020 um 12.441 % steigt. Die Zahl der neuen Internetnutzer betrug im Jahr 2020 319 Millionen und wächst täglich um 7 % oder fast eine Million neue Nutzer. Mit mehr Menschen steigt auch die Suchaktivität. Google, das besitzt 91,9 % des Internet-Suchmarktes und bearbeitet 8,5 Milliarden Suchanfragen pro Tag. Das ist ein Anstieg von 5,6 Milliarden im Jahr 2021 und ungefähr 99.000 Suchanfragen pro Sekunde. So viel zum Thema Datenwachstum!
Weshalb es so viele Datenanbieter gibt
Unternehmen brauchen Datenanbieter. All diese Daten liegen in unterschiedlichen Formaten und an verschiedenen Orten vor. Einige davon können mit bescheidenem Aufwand sicher und gewinnbringend kombiniert werden. Andere erfordern mehr. Aber im Allgemeinen müssen alle Daten "sauber" und strukturiert sein. Auf diese Weise können sie mit anderen, ergänzenden Datenquellen zur Analyse kombiniert und anschließend für Maßnahmen visualisiert werden. Dies ist die Aufgabe der Datenanbieter.
Und da es viele Quellen und Arten von Daten gibt, die für Unternehmen nützlich sind, gibt es auch viele Möglichkeiten, diese Daten nützlich zu machen. Dies kann es schwierig machen, verschiedene Anbieter und Dienstleistungen von einem Projekt zum anderen zu vergleichen. Jedes Projekt konzentriert sich auf unterschiedliche Ergebnisse, Branchen, Kundentypen usw., und nicht jeder Datenanbieter kann alle Parameter perfekt abdecken. Abgesehen von den unterschiedlichen Daten gibt es auch unterschiedliche - oft firmeneigene - Methoden, die einen Vergleich erschweren können.
Natürlich sind auch die Datenanbieter nicht alle gleich. Bei der großen Menge an Daten, die zur Verfügung stehen, sind viele von ihnen nicht wertvoll, werden nicht solide beschafft oder mit minderwertiger Datenwissenschaft aggregiert. Diese Faktoren können die Leistung und den tatsächlichen Wert der Daten beeinträchtigen. Die Berücksichtigung dieser und einiger anderer Schlüsselfaktoren kann zu einer Zusammenarbeit beitragen, von der alle Beteiligten profitieren.

Warum die Manipulation von Daten nicht immer eine schlechte Sache ist
Alle Daten werden manipuliert. Das müssen sie auch sein, um brauchbar zu sein. Vielleicht werden sie zum Beispiel in alphabetischer Reihenfolge sortiert oder nach Postleitzahlen oder früherer Produktnutzung. Vielleicht werden sie manipuliert, um Website-Verwaltungsprotokollen zu entsprechen, die sich auf Webprotokolle oder die Sicherheit der Kunden-ID konzentrieren.
Diese Art der Manipulation macht die Daten für Unternehmen nützlich und ermöglicht es, die Daten zu kombinieren, zu analysieren und schließlich zu visualisieren. Aber wie viel Manipulation ist gut, und wie viel ist zu viel?
Große Datensätze bieten den Unternehmen eine größere Bandbreite an Daten, wodurch sichergestellt werden kann, dass die Schlussfolgerungen repräsentativ für eine marktfähige Zielgruppe sind. Bei der Zusammenführung von Datensätzen müssen jedoch auch zahlreiche Faktoren berücksichtigt werden, von der Firmengrafik und den Zeiträumen bis hin zum Abgleich der Datenkategorien, um sicherzustellen, dass die Schlussfolgerungen dem gewünschten Umfang und der gewünschten Größenordnung entsprechen.
Große Datensätze können auch unhandlich werden, was die Herausforderungen bei der Ermittlung spezifischer und umsetzbarer Erkenntnisse widerspiegelt, die oft mit kleinen Teilmengen von Daten deutlicher werden, aber dennoch den Umfang und die Kohärenz des größeren, reichhaltigeren Datensatzes benötigen, um Ergebnisse zu validieren.
Die wichtigsten Datenmanipulationen haben mit Quantität und Qualität zu tun - und sie sind notwendig.
Die Zutaten guter Daten - verifiziert, validiert, datenschutzkonform
Viele der Standardmanipulationen, die Unternehmen an Daten vornehmen, haben mit folgenden Aspekten zu tun Qualitätdie aus drei großen Faktoren besteht: Validierung, Überprüfung und Datenschutz.
- DieÜberprüfung stellt sicher, dass die Datensätze mit echten Personen und nicht mit Bots verknüpft sind und dass sie für den jeweiligen Zweck korrekt, aktuell und vollständig sind. Ungenaue, veraltete und unvollständige Daten können zu unnötiger Verschwendung und Kosten führen und die Kundenbeziehungen schwächen.
- Validierte Daten sind Daten, die integriert sind, d. h. sie erfüllen logische und strukturelle Anforderungen für Verarbeitungs- und Analysezwecke: Postleitzahlen und Telefonnummern haben die richtige Anzahl und Art von Zeichen für den jeweiligen Standort, frühere Käufe sind den Kunden korrekt zugeordnet usw. Daten, die diese Anforderungen nicht erfüllen, können von Analysen oder anderen Verwendungen ausgeschlossen werden, was zu höheren Kosten und verlorenen Erkenntnissen führt.
- Die Anforderungen an dieEinhaltung des Datenschutzes gewährleisten, dass die Präferenzen der Verbraucher in Bezug auf die Speicherung und Verwendung ihrer personenbezogenen Daten ihren Erwartungen entsprechen. Wenn dies nicht der Fall ist, kann dies ein erhebliches finanzielles und rufschädigendes Risiko darstellen.

Aber selbst gute, hochwertige Daten reichen nicht aus
Jetzt, wo die Daten sauber sind, brauchen sie einen Kontext. Ohne Kontext ist es viel schwieriger, verwertbare Erkenntnisse für die Kundengewinnung und -bindung, die Produktverbesserung, die Umsatzoptimierung und vieles mehr zu gewinnen, egal wie sauber und abgestimmt der Datensatz ist.
Wie die Hinzufügung von Echtzeit-Verhaltensdaten den Datensätzen Kontext hinzufügt und Ergebnisse sicherstellt
Der Kontext ist ein Produkt aus realen Daten, die von echten Verbrauchern bei ihren Online-Aktivitäten erzeugt werden, z. B. beim Teilen eines Videos, beim Herunterladen einer Broschüre oder bei der Suche nach Rezepten, Flügen oder Veranstaltungstickets usw.
Echte Verhaltens- und Interessendaten sind deterministisch, da sie repräsentativ für aktuelle, echte Online-Interaktionen und Interessen sind. Sie sind authentisch, leistungsstark und können in Echtzeit zur Verfügung gestellt werden. Stellen Sie sich diese Daten wie "vom Bauernhof auf den Tisch" vor, mit einem geringeren Risiko, sie übermäßig zu verarbeiten oder fehlerhafte oder unnötige Schichten der Datenwissenschaft oder Modellierung anzuwenden. Es handelt sich um echte Daten in Echtzeit, die visualisiert und mit verwertbaren Erkenntnissen versehen sind. So lassen sich aufkommende Verbrauchertrends und sich ändernde Käuferpräferenzen vorhersagen.
Die Datenwissenschaft wird in der Datenbranche immer Anwendung finden. Die Chance besteht darin, diese Wissenschaft auf echte Daten anzuwenden und nicht auf Daten, die bereits in irgendeiner Weise modelliert wurden. Die Anwendung von Datenwissenschaft, die bereits modelliert wurde, kann die Authentizität und den Wert der ursprünglichen Daten verwässern.
Steven Casey hat es vielleicht am besten ausgedrückt, als er in seinem Team Forrester-Bericht 2019: Unternehmen sollten "mehr darauf achten, was ihre potenziellen Kunden tun, als darauf, was sie sagen" [Hervorhebung hinzugefügt]. Echte Verhaltens- und Interessendaten helfen den Teams, genau das zu tun.
In einer Welt, die bereits mit Daten überfüllt ist, besteht die Chance darin, den verborgenen Wert aufzudecken. Das Hinzufügen von mehrschichtigen Analysen, Modellierungen und anderen datenwissenschaftlichen Verfahren kann diesen Wert verdecken oder schwächen.



