
Compression & format de données pour le stockage de fichiers journaux
par Safa Shah, directeur technique
Chaque entreprise de technologie stocke maintenant des journaux pour le traitement futur. Le Conseil facile est d'utiliser la compression et assurez-vous que les journaux sont complets et utilisables par tout le monde. Mais quel format de compression ces fichiers journaux doivent-ils être? Il y a une gamme déroutante des options de compression-LZ0, Snappy, gzip, bzip2 etc., et les formats multiples dans lesquels les données peuvent être stockées-texte, formats binaires comme les mémoires tampons de protocole, Avro, MessagePack etc. et les hybrides comme les dossiers de séquence, RCFile, ORCFile etc.
Applications de fichiers journaux
Toute application qui va utiliser les fichiers journaux est appelée application de fichier journal. UN grand nombre d'entreprises utilisent maintenant des «grandes technologies de données» comme Hadoop, NoSQL, Hive etc. Ainsi, le format des fichiers journaux doit prendre en charge le traitement facile sans aucune exigence indue pour qu'ils soient largement utilisés.
Compression
Ci-dessous un graphique rapide de Yahoo sur la façon dont les algorithmes de compression différents rang dans le rapport de compression vs compresser/décompresser le temps.
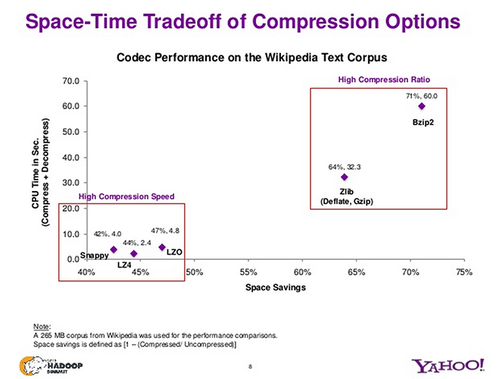
Comme vous pouvez le voir, les algorithmes de compression plus rapide ont des ratios de compression pires. Pour le stockage de fichiers journaux, qui sont écrits une fois puis utilisés plusieurs fois, le temps de décompression atteint à chaque fois que les fichiers journaux sont utilisés pour l'analyse, ou par toute application.
Une autre condition qui apparaît généralement pour Hadoop, est que les fichiers journaux qui sont stockés doivent être scindables. Il en est ainsi que plusieurs mappeurs peuvent travailler dessus en même temps. Examinons les différents algorithmes de compression pour voir si elles sont scindables ou non:

Comme vous pouvez le voir, seul bzip2 est divisible. Est-ce que cela signifie que nous devrions avoir tous les fichiers journaux compresses en utilisant bzip2? Il est divisible et a le rapport de compression très élevé, mais le compromis est que chaque application qui doit utiliser ces fichiers de log aura également le temps CPU très élevé nécessaire pour la décompression. Pour contrecarrer l'exigence de temps processeur élevé, il existe un nouveau format disponible, l'algorithme LZMA, qui encode les fichiers dans l'extension. XZ. Le noyau Linux est maintenant disponible au format. XZ au lieu de. bzip2. LZMA donne le même rapport de compression que bzip2, et est également très rapide.
Le problème avec ceci est que bzip2 n'est pas très populaire, et. XV est encore moins. Les applications devront trouver des codes à l'appui, ce qui peut être problématique en fonction de votre environnement.
Formats de conteneurs
Il y a nombre d'autres formats qui apparaîtront dans votre recherche et ci-dessous est résumé rapide sur eux.
Hadoop utilise des fichiers de séquence (et des fichiers de mappage) pour un format binaire, qui est divisible. Le principal cas d'utilisation est de Club plusieurs fichiers plus petits dans les fichiers de séquence plus volumineux. Hive utilise à la fois RCFile et ORCFile. Ces formats sont optimisés pour l'interrogation sur plusieurs lignes. Ils sont tous deux groupés par lignes et à l'intérieur ont une disposition columnaire. La compression peut être appliquée au-dessus des groupes de lignes. Ces formats sont excellents si votre cas d'utilisation principale de stocker des fichiers journaux fait l'analyse dans la ruche (ou ses dérivés).
Les formats binaires d'usage général comme les mémoires tampons de protocole, Avro et MessagePack sont des formats binaires de sérialisation/désérialisation et probbaly beaucoup plus efficace que juste JSON/Text simple. Mais la plupart de ces formats binaires ne sont pas divisible, et ils ont besoin d'un soutien spécialisé dans les applications de log.
Le texte est l'un des formats les plus populaires. Nous pouvons laisser les fichiers journaux dans le texte et laisser traiter la compression de rendre l'espace efficace.