
Compressione e formato dati per la memorizzazione dei file di registro
di Kalpak Shah, direttore tecnico
Ogni azienda tecnologica sta ora memorizzando i registri per l'elaborazione futura. Il consiglio più semplice è quello di utilizzare la compressione e assicurarsi che i log siano completi e utilizzabili da tutti. Ma in quale formato di compressione devono essere inseriti questi file di log? Esiste una gamma sconcertante di opzioni di compressione - LZ0, Snappy, Gzip, Bzip2 ecc., e molteplici formati in cui i dati possono essere memorizzati - testo, formati binari come i buffer di protocollo, Avro, MessagePack ecc. e quelli ibridi come i file di sequenza, RCFile, ORCFile ecc.
Applicazioni dei file di registro
Qualsiasi applicazione che utilizzerà i file di log è chiamata Log File Application. Un gran numero di aziende stanno ora utilizzando "Big Data Technologies" come Hadoop, NoSQL, Hive ecc. Quindi il formato dei file di log dovrebbe supportare una facile elaborazione senza requisiti eccessivi per essere ampiamente utilizzato.
Compressione
Di seguito è riportato un rapido grafico di Yahoo su come i diversi algoritmi di compressione si posizionano nel rapporto di compressione rispetto al tempo di compressione/decompressione.
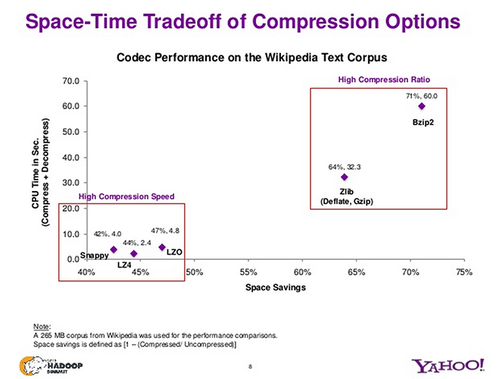
Come si può vedere, gli algoritmi di compressione più veloci hanno rapporti di compressione peggiori. Per la memorizzazione dei file di log, che vengono scritti una volta e poi utilizzati più volte, il tempo di decompressione colpisce ogni volta che i file di log vengono utilizzati per l'analisi, o da qualsiasi applicazione.
Un altro requisito che di solito si presenta per Hadoop, è che i file di log che vengono memorizzati devono essere divisibili. Questo per consentire a più Mapper di lavorare su di essi contemporaneamente. Diamo un'occhiata ai diversi algoritmi di compressione per vedere se sono divisibili o meno:

Come potete vedere, solo il bzip2 è divisibile. Questo significa che dovremmo avere tutti i file di log comprimibili con bzip2? È divisibile e ha un rapporto di compressione molto alto, ma il compromesso è che ogni applicazione che ha bisogno di utilizzare questi file di log avrà anche un tempo di CPU molto alto necessario per la decompressione. Per contrastare l'elevato tempo di CPU richiesto, è disponibile un nuovo formato - l'algoritmo LZMA - che codifica i file con estensione .xz. Il kernel Linux è ora disponibile in formato .xz invece di .bzip2. LZMA fornisce un rapporto di compressione simile a quello di bzip2, ed è anche molto veloce.
Il problema è che bzip2 non è molto popolare, e .xv lo è ancora meno. Le applicazioni dovranno trovare dei codici per supportare questo, il che può essere problematico a seconda del vostro ambiente.
Formati dei contenitori
Ci sono molti altri formati che appariranno nella tua ricerca e qui sotto c'è un rapido riepilogo su di essi.
Hadoop utilizza i file di sequenza (e i file di mappa) per un formato binario, che è divisibile. Il caso d'uso principale è quello di raggruppare più file più piccoli in file di sequenza più grandi. Hive usa sia RCFile che ORCFile. Questi formati sono ottimizzati per l'interrogazione su più file. Sono entrambi raggruppati per righe e all'interno hanno un layout a colonne. La compressione può essere applicata sopra i gruppi di righe. Questi formati sono ottimi se il vostro principale caso d'uso per la memorizzazione dei file di log è l'analisi in Hive (o suoi derivati).
I formati binari per uso generale come Protocol Buffers, Avro e MessagePack sono formati binari di serializzazione/deserializzazione e probbaly molto più efficienti del semplice json/testo. Ma la maggior parte di questi formati binari non sono divisibili e necessitano di un supporto specializzato nelle applicazioni di log.
Il testo è uno dei formati più popolari. Possiamo lasciare i file di log nel testo e lasciare che la compressione si occupi di rendere lo spazio efficiente.