
by Kalpak Shah, Engineering Director
Every technology company is now storing logs for future processing. The easy advice is to use compression and make sure logs are complete and usable by everyone. But what compression format should these log files be in? There is a bewildering range of compression options – LZ0, Snappy, Gzip, Bzip2 etc., and multiple formats in which data can be stored – text, binary formats like protocol buffers, Avro, MessagePack etc and hybrid ones like sequence files, RCFile, ORCFile etc.
Log File Applications
Any application that is going to use the log files is called Log File Application. A large number of companies are now using “Big Data Technologies” like Hadoop, NoSQL, Hive etc. So log files format should support easy processing without any undue requirements for them to be widely used.
Compression
Below is a quick graph from Yahoo about how the different compression algorithms rank in compression ratio vs compress/decompress time.
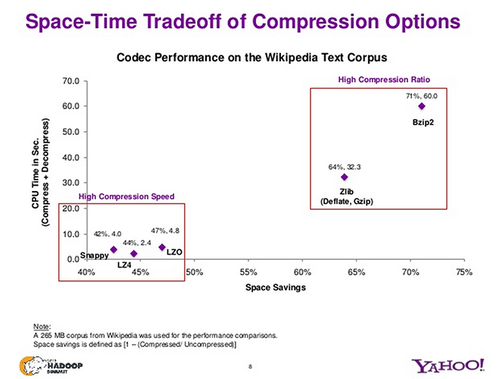
As you can see, the faster compression algorithms have worse compression ratios. For log file storage, which are written once and then used multiple times, the decompression time hit every time the log files are used for analysis, or by any application.
Another requirement that usually shows up for Hadoop, is that log files that are stored need to be splittable. This is so that multiple Mappers can work on it at the same time. Let’s look at the different compression algorithms to see whether they are splittable or not:

As you can see, only bzip2 is splittable. Does this mean we should have all log files compresses using bzip2? It is splittable and has very high compression ratio, but the tradeoff is that every application that needs to use these log files will also have very high CPU time needed for decompression. To Counteract the high CPU time requirement, there is a new format available — LZMA algorithm — that encodes files in .xz extension. Linux Kernel is now available in .xz format instead of .bzip2. LZMA gives similar compression ratio as bzip2, and is also very fast.
The issue with this is that bzip2 is not very popular, and .xv is even less. Applications will need to find codes to support this, which can be problematic depending upon your environment.
Container Formats
There are number of other formats which will show up in your research and below is quick summary on them.
Hadoop uses Sequence Files (and Map Files) for a binary format, which is splittable. The main use case is to club multiple smaller files into larger sequence files. Hive uses both RCFile and ORCFile. These formats are optimized for querying across multiple rows. They are both grouped by rows and inside have a columnar layout. Compression can be applied on top of row groups. These formats are great if your main use case of storing log files is doing analysis in Hive (or its derivatives).
General purpose binary formats like Protocol Buffers, Avro and MessagePack are binary serialization/deserialization formats and probbaly a lot more efficient than just plain json/text. But most of these binary formats are not splittable, and they need specialized support in Log Applications.
Text is one of the most popular formats. We can leave the log files in text and let compression deal with making it space efficient.