
Compressão e Formato de Dados para Armazenamento de Arquivos de Log
por Kalpak Shah, Diretor de Engenharia
Todas as empresas de tecnologia estão agora armazenando logs para processamento futuro. O conselho fácil é usar a compressão e garantir que os logs sejam completos e utilizáveis por todos. Mas em que formato de compressão devem estar esses arquivos de log? Existe uma gama confusa de opções de compressão - LZ0, Snappy, Gzip, Bzip2 etc., e múltiplos formatos nos quais os dados podem ser armazenados - texto, formatos binários como buffers de protocolo, Avro, MessagePack etc. e híbridos como arquivos sequenciais, RCFile, ORCFile etc.
Aplicações de arquivo de log
Qualquer aplicativo que vai usar os arquivos de log é chamado de Log File Application. Um grande número de empresas está agora a utilizar "Big Data Technologies" como a Hadoop, NoSQL, Hive, etc. Assim, o formato dos ficheiros de log deve suportar um processamento fácil sem quaisquer requisitos indevidos para que sejam amplamente utilizados.
Compressão
Abaixo está um gráfico rápido do Yahoo sobre como os diferentes algoritmos de compressão se classificam na razão de compressão vs tempo de compressão/descompressão.
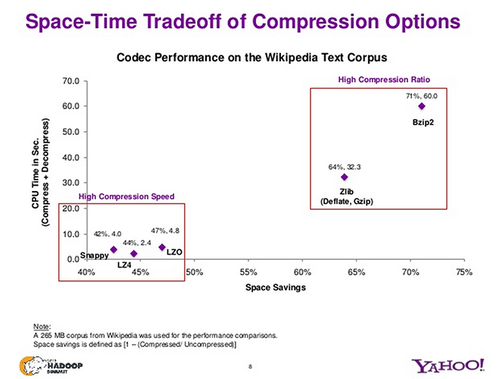
Como você pode ver, os algoritmos de compressão mais rápida têm taxas de compressão piores. Para armazenamento de arquivos de log, que são escritos uma vez e depois usados várias vezes, o tempo de descompressão é atingido toda vez que os arquivos de log são usados para análise, ou por qualquer aplicativo.
Outro requisito que normalmente aparece para o Hadoop, é que os arquivos de log que são armazenados precisam ser divisíveis. Isto é para que vários mapeadores possam trabalhar nele ao mesmo tempo. Vamos olhar para os diferentes algoritmos de compressão para ver se eles são divisíveis ou não:

Como você pode ver, apenas bzip2 é divisível. Isso significa que devemos ter todos os arquivos de log compactados usando bzip2? Ele é divisível e tem uma taxa de compressão muito alta, mas o tradeoff é que toda aplicação que precisa usar esses arquivos de log também terá um tempo muito alto de CPU necessário para descompressão. Para compensar o alto requerimento de tempo da CPU, há um novo formato disponível - algoritmo LZMA - que codifica arquivos na extensão .xz. O Kernel Linux está agora disponível no formato .xz em vez de .bzip2. O LZMA dá uma taxa de compressão similar à do bzip2, e também é muito rápido.
A questão com isso é que bzip2 não é muito popular, e .xv é ainda menos. As aplicações terão de encontrar códigos para suportar isto, o que pode ser problemático dependendo do seu ambiente.
Formatos dos recipientes
Existem vários outros formatos que aparecerão na sua pesquisa e abaixo está um resumo rápido sobre eles.
O Hadoop usa arquivos de seqüência (e arquivos de mapas) para um formato binário, que é divisível. O caso de uso principal é para agrupar vários arquivos menores em arquivos de seqüências maiores. O Hadoop utiliza tanto o RCFile como o ORCFile. Estes formatos são optimizados para consulta em várias filas. Ambos são agrupados por filas e no seu interior têm um layout em colunas. A compressão pode ser aplicada no topo dos grupos de linhas. Estes formatos são óptimos se o seu principal caso de utilização for o armazenamento de ficheiros de registo em Hive (ou as suas derivadas).
Formatos binários de uso geral como Protocol Buffers, Avro e MessagePack são formatos de serialização/deserialização binários e probbaly muito mais eficientes do que apenas json/texto simples. Mas a maioria destes formatos binários não são separáveis, e precisam de suporte especializado em Aplicações de Log.
O texto é um dos formatos mais populares. Podemos deixar os arquivos de log em texto e deixar a compressão lidar com a eficiência do espaço.