
數據幾乎無處不在,而且還在不斷增加。引用 三葉草,“74 ZB的數據將在2021年創建。這比2020年的59澤位元組和2019年的41澤位元組有所上升。為了將其置於上下文中,請考慮一澤位元組是一萬億千兆位元組,這將填充近20億個512GB的iPhone。
所有這些數據來自哪裡?
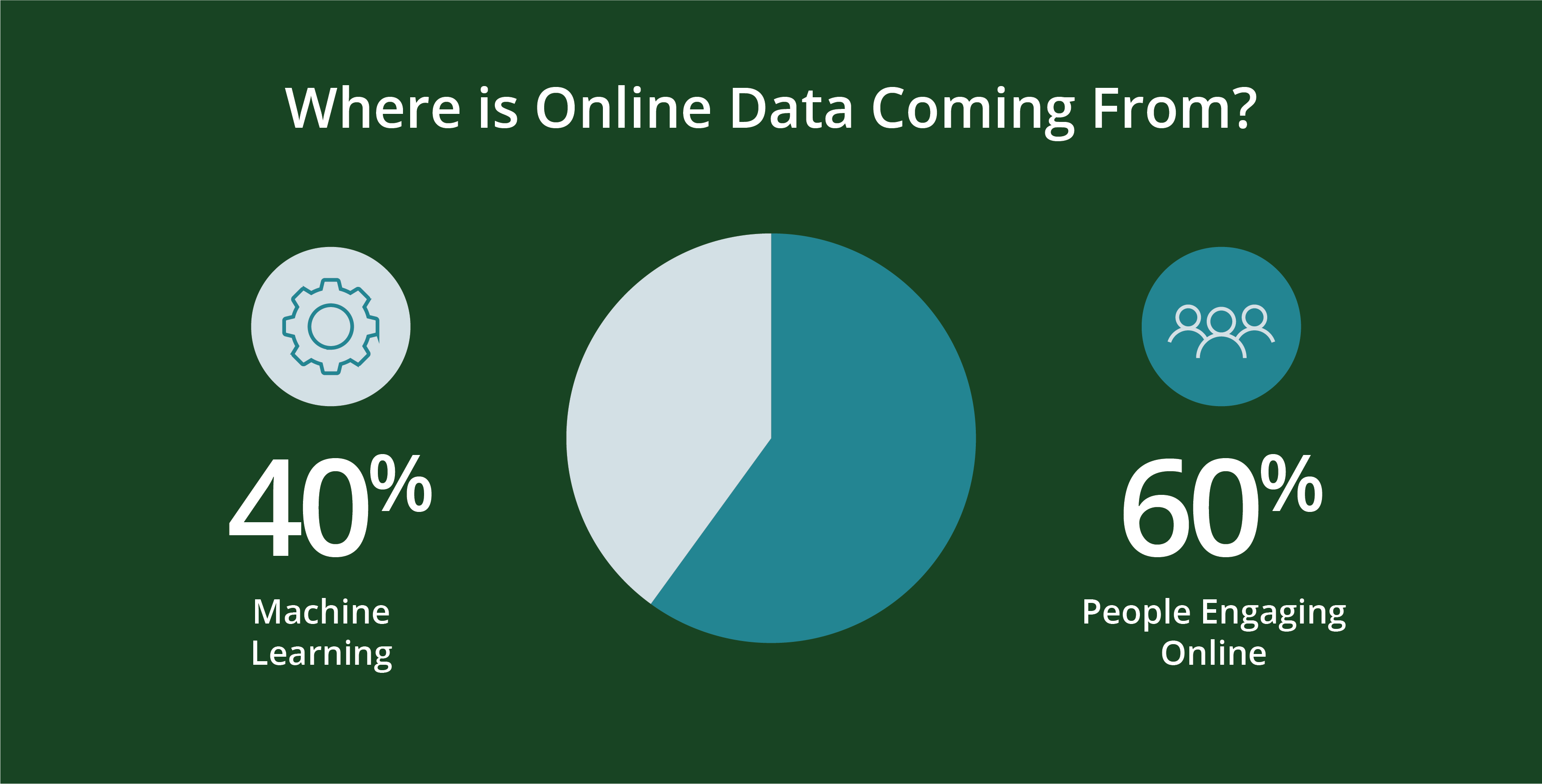
人及其創建的程式設計會生成數據。更具體地說, 今天大約60%的在線數據是由人生成的,其餘 40% 是在 Web 紀錄、API、安全端點、消息佇列和感測器數據等腳本中機器生成的。
考慮一下剛剛結束 世界人口的一半是數位活躍的——這是近50億人。當然,數位生活以不同的速度滲透到全球不同地區。雖然90%的北美和歐洲人是數字活躍的,但其他地區正在以驚人的速度增長 - 例如非洲,從2000年到2020年增長了12,441%。2020年新增互聯網使用者為3.19億,每天增長7%或近100萬新使用者。隨著人數的增加,搜索活動也越來越多。谷歌,哪個 擁有91.9%的互聯網搜索市場,每天處理85億次搜索.這是從 2021年為56億 和大致 每秒 99,000 次搜索.談論數據增長!
這就是為什麼有這麼多數據供應商的原因
企業需要數據供應商。所有這些數據都以不同的格式和位置存在。其中一些可以通過適度的努力安全且有利可圖地結合在一起。其他人需要更多。但總的來說,所有數據都必須是“乾淨”和結構化的。這樣,它可以與其他互補的數據源結合使用進行分析,然後可視化以進行操作。這是數據提供者的工作。
由於有許多來源和類型的數據對企業有用,因此也有很多方法可以使這些數據有用。這使得比較不同專案的不同供應商和服務變得困難。每個專案都專注於不同的結果、行業、客戶類型等,每個數據提供者都無法完美地適應每個參數。除了數據可變性之外,還有不同的方法(通常是專有的),這使得比較具有挑戰性。
當然,數據提供者也不是生來平等的。由於有如此多的數據可用,其中大部分沒有價值,或者沒有可靠的來源,或者與低級數據科學匯總。這些因素可能會影響性能和數據的實際值。牢記這些因素和其他一些關鍵因素有助於確保雙贏的協作。

為什麼操縱數據並不總是一件壞事
所有數據都縱。它必須是,才能可用。例如,它可能按字母順序排序,或者根據郵遞區號或以前的產品使用方式排序。也許它縱以適應專注於 Web 紀錄或客戶 ID 安全性的網站管理協定。
這種類型的操作使數據對企業有用,並允許數據被組合,分析並最終可視化。但是,多少操縱是好的,多少是太多的呢?
大型數據集為公司提供了更廣泛的數據,這可以確保結論代表具有市場價值的受眾群體。但是,合併數據集還必須解決從公司圖形和時程表到數據類別對齊的眾多因素,以確保結論符合所需的範圍和規模。
大型數據集也可能變得笨拙,這反映了識別特定和可操作見解的挑戰,這些見解通常對於較小的數據子集更為明顯,但仍然需要更大,更豐富的數據集的規模和一致性來驗證結果。
事實上,最重要的數據操作與數量和質量有關,而且它們是必要的。
良好數據的要素 — 經過驗證的、經過驗證的、符合隱私保護的
公司應用於數據的許多標準操作都與 品質,它有三個主要因素:確認、驗證和隱私。
- 驗證 可確保數據記錄與真實人員相關聯,而不是與機器人相關聯,並且它們對於手頭的目的來說是準確,最新和完整的。 不準確、過時和不完整的數據可能導致不必要的浪費和成本,並削弱客戶關係。
- 經過驗證的 數據是集成的數據,也就是說,它滿足處理和分析目的的邏輯和結構要求:郵遞區號編碼和電話號碼具有相關位置的正確編號和字元類型,先前的購買與客戶正確關聯,等等 。 導致更高的成本和丟失的見解。
- 隱私合規性 要求確保消費者對個人數據的存儲和使用偏好符合他們的期望。 錯過此標記可能會導致相當大的金錢和聲譽風險。

但即使是好的、高質量的數據也是不夠的
現在數據是乾淨的,它需要上下文。如果沒有上下文,無論數據集多麼乾淨和一致,都很難確定可操作的見解,以用於從客戶獲取和保留到產品增強,收入優化等各個方面。
添加即時行為數據如何為數據集添加上下文並確保結果
上下文是真實消費者在其在線活動中生成的真實數據的產物,例如共用視頻,下載摺頁冊或搜索食譜,航班或活動門票等。
真實的行為和興趣數據是確定性的,因為它代表了最近的真實在線互動和興趣。它真實,功能強大,可以即時提供。可以將其視為“從農場到表格”的數據,過度處理數據或應用錯誤或不必要的數據科學或建模層的風險較小。只是真實的東西,即時,可視化和充滿可操作的見解。因此,它可以預測新興的消費趨勢和不斷變化的買家偏好。
數據科學將始終應用於數據行業。機會是將科學應用於真實數據,而不是已經以某種方式建模的數據。應用已經建模的數據科學可能會削弱原始數據的真實性和價值。
也許史蒂文·凱西在他的團隊中說得最好。 2019 年 Forrester 報告企業應該「更多地關注你的潛在客戶做了什麼, 而不是他們說什麼」 [著重號是後加的]。真實的行為和興趣數據可以幫助團隊做到這一點。
在一個已經充斥著數據的世界中,機會是揭示隱藏的價值。逐層添加分析、建模和其他數據科學可能會模糊或削弱這一價值。



