Registrazione eventi asincrona e ad alte prestazioni a ShareThis
da Fadi Obeid, Ingegnere capo & Tech Lead, Prodotti pubblicitari
Se avete lavorato su o con il tempo reale, probabilmente avete avuto a che fare con la registrazione degli eventi. A ShareThis, ci occupiamo di tempo reale - raccogliamo i segnali sociali man mano che si verificano, applichiamo la logica di business a questi segnali e, infine, trasformiamo questi segnali in complesse regole di ad-targeting.
In questo post parleremo della registrazione degli eventi in scala. Una versione semplificata del nostro gasdotto è la seguente:
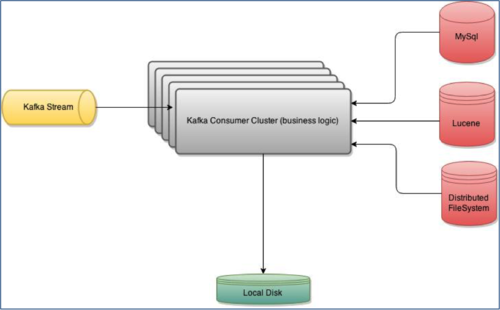
Il torrente Kafka sta pompando circa 800 milioni-1 miliardo di eventi/giorno. Ogni evento si espande in una media di 12 eventi virtuali, quindi la logica di business all'interno del cluster di consumatori Kafka dovrà elaborare e valutare 9-12 miliardi di eventi al giorno e registrare su disco gli eventi qualificanti.
Inizialmente, avevamo una mappatura 1×1 dell'evento grezzo rispetto all'evento virtuale, che non era un grosso problema dato che avevamo "abbastanza macchine". La capacità del cluster era di 3 c3.xgrandi istanze ed era supportata da un logger sincrono autocostruito.
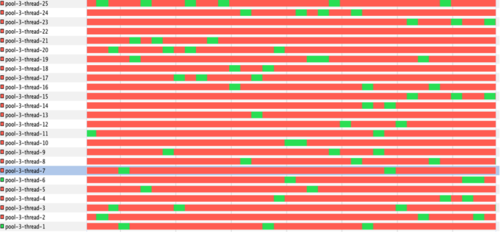
Con il tempo, la mappatura è aumentata - da 1×1 a 1×3 e così via. Ogni scatola Kafka nel cluster funzionava con 25 thread, e a carico, l'effetto di bloccare l'operazione di scrittura come visto in questo frammento di codice era paralizzante. L'esecutore del pool di thread era in ritardo nella sua capacità di servire le richieste in arrivo, e l'offset Kafka iniziava a rimanere indietro, a volte fino ad un punto in cui non riusciva mai a recuperare il ritardo.
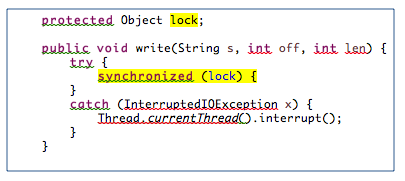
Un profilo delle filettature in esecuzione ha mostrato che le filettature sono bloccate quasi sempre, yikes!
Abbiamo iniziato a valutare le nostre opzioni. La nostra lista si è ridotta a:
- Aggiungere altre macchine
- Registratore asincrono di legname asincrono di provenienza nazionale
- Log4j2 asincrono + disgregatore + RandomAccessFile
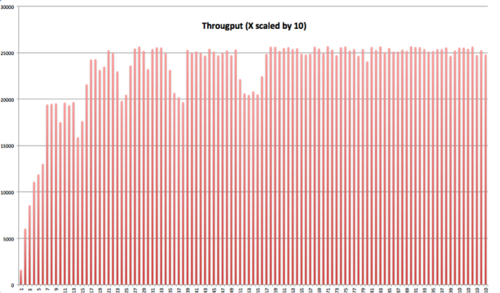
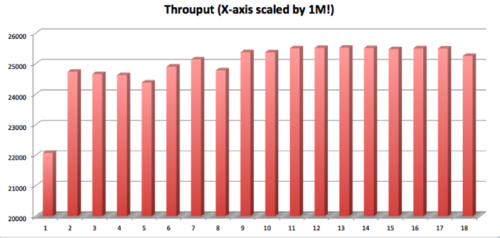
Siamo passati attraverso i pro e i contro e siamo atterrati su Log4j2. Abbiamo fatto un benchmarking e i risultati sono stati molto impressionanti. Ai fini di questo post, mostriamo due grafici: il primo mostra il rendimento a basso carico, e il secondo mostra il rendimento ad alto carico. La parte bella è stata la facilità con cui è stato possibile inserirlo nel progetto esistente, il supporto e l'ampia documentazione.
In conclusione, possiamo tranquillamente affermare che la nostra scelta "log4j2 asincrono + disruptivo + RandomAccessFile" per la registrazione è stata quella giusta. Se state attraversando un processo simile, vi raccomandiamo vivamente di profilare la vostra applicazione, di definire le vostre opzioni e di effettuare un benchmarking.